




Meet the Sardine Rules Engine
From the very beginning, Sardine has been by the fraud squad, for the fraud squad. And simultaneously by data engineers for data engineers.
At our core we're a machine learning and data science company, but we know a flexible and adaptable rules engine is still critical for catching new typographies, patterns and challenges.
We think our rules engine rules.
In this piece we cover
- What is a rules engine?
- How does a rules engine work?
- The key features of the Sardine rules engine
1. What is a Rules engine?
A rules engine is a way for fraud and compliance operations teams to create a logical expression. At the simplest level “if x happens then do y.” At the complex level it can create complex chains of logic to detect and manage sophisticated risks.
A Rules Engine is:
- Human readable: Clarity on why certain transactions were flagged as high-risk
- Faster reactions: When new fraud pattern spikes, risk analysts can put together rules instantly to block frauds without waiting for model retraining
- Highly specific: It can capture very specific business requirements for certain use cases that might not have enough data for training ML models
2. How the Sardine Rules Engine Functions for Users
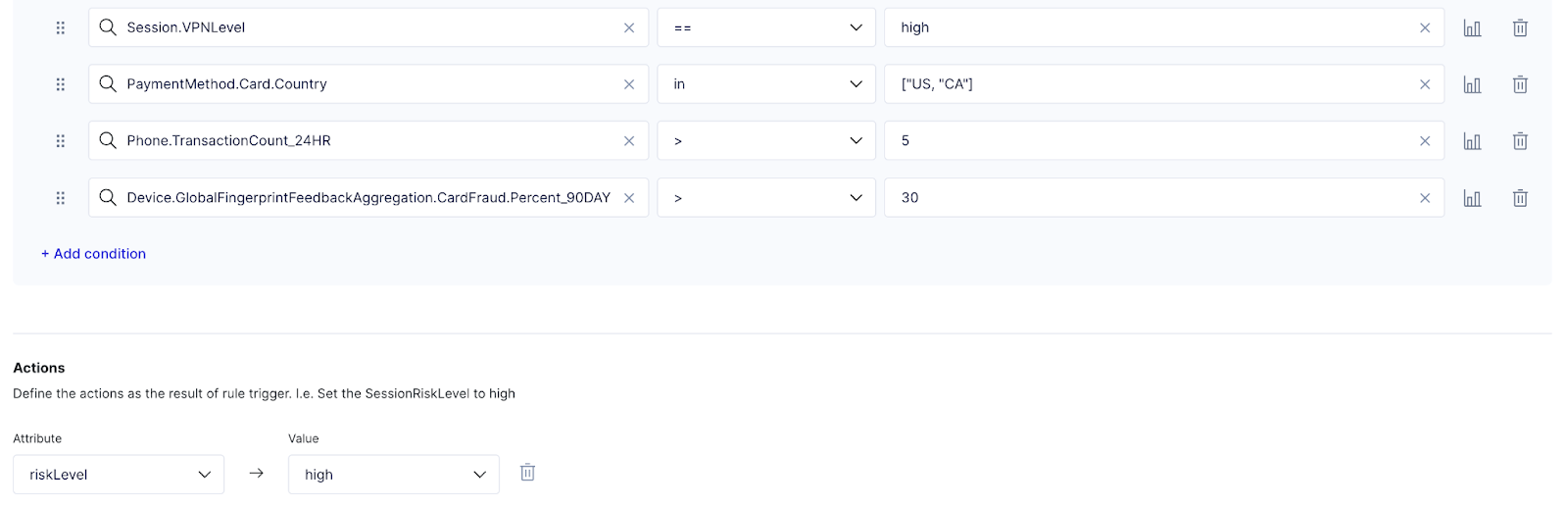
Below is an example of a rule you can write using Sardine’s rule editor
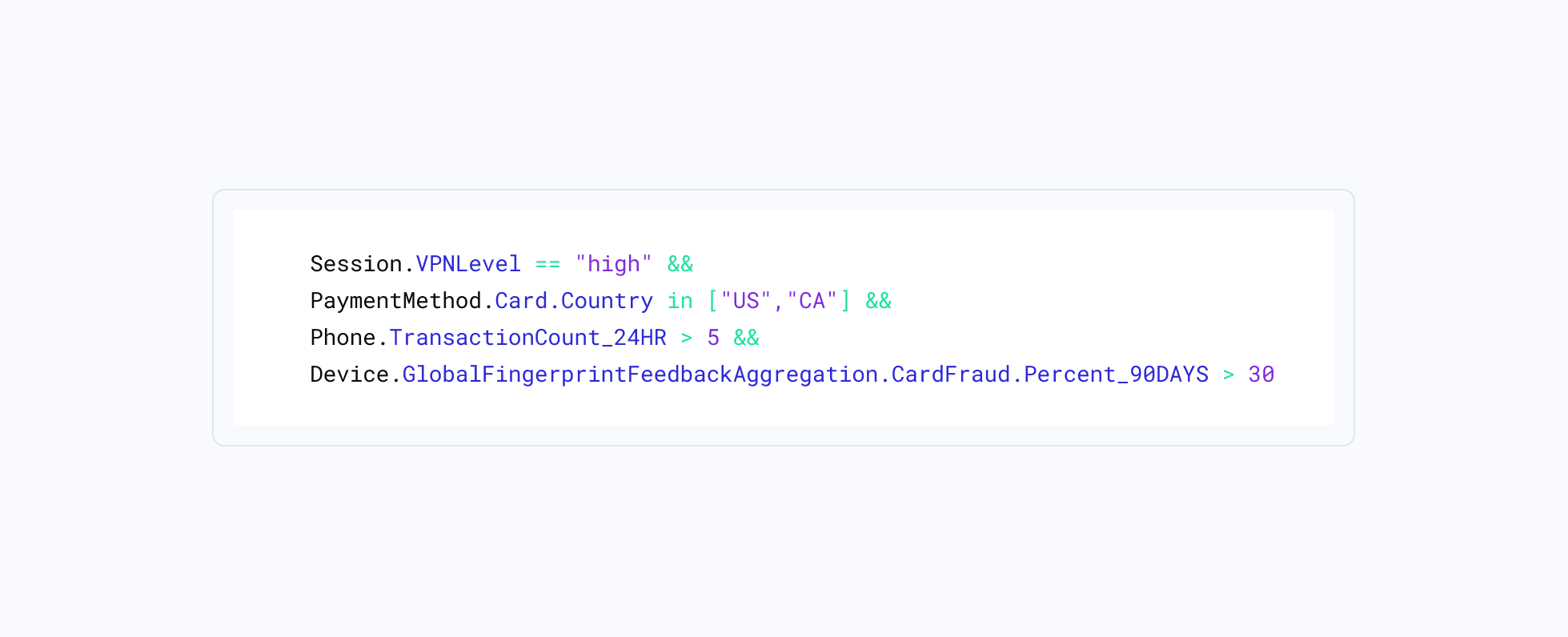
💡 Rules are made of various inputs Sardine computes thousands of features in real-time. These features include:
- Inhouse data signals (e.g., if the session uses VPN)
- Data we get from third-party data providers (e.g., credit card issuer country),
- Real-time aggregations (e.g., how many transactions are done from the same phone number in the last 24 hours)
- Signals from our consortium (e.g., how many fraudulent transactions have we seen from the same device fingerprint).
💡 Writing rules: Rules are written as logical expressions, as shown in the above screenshot. Based on the rule evaluation result, a rule can be assigned an action - e.g., mark the transaction as high risk, put it in a review queue, require 2FA, etc. Operations like equals (==), AND, OR, is greater or less than can also be combined to create complex rules like the one shown above.
- Session level EQUALS high
- Payment card INLCLUDES Canada or the USA
- The transactions on that device in the past 24 hours are GREATER THAN 5
- Aggregation percent is GREATER THAN 30
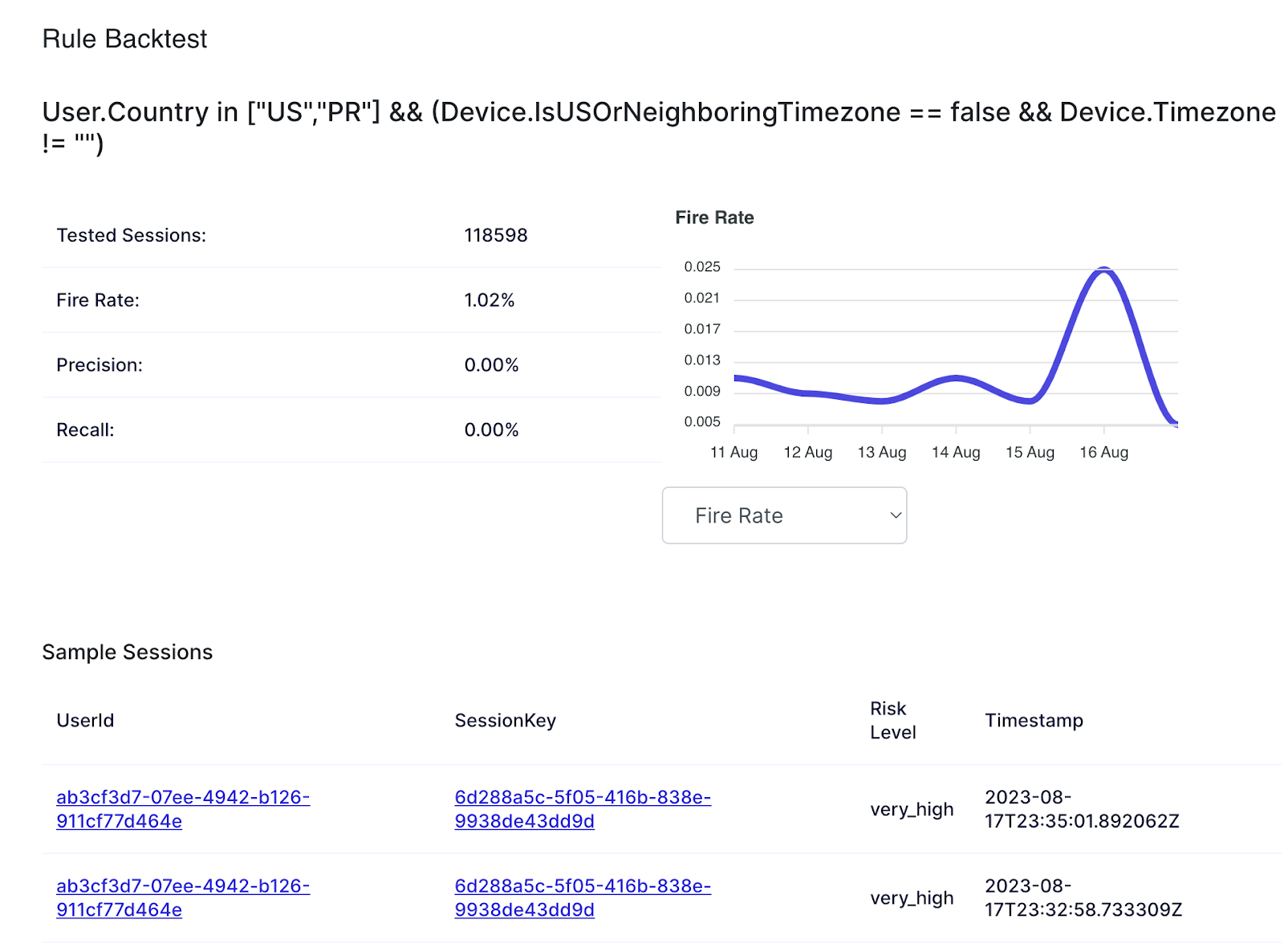
💡 Testing and "Backtests" preview rule performance: When creating or editing rules, users can backtest them against historical data. This will give you confidence this rule won’t decline too many transactions and return precision and recall statistics over time if feedback labels have been provided. After creating/editing rules, changes will be available within a few minutes. All rule execution records are stored; users can see data and performance metrics afterward.
3. Why the Sardine rules engine rules.
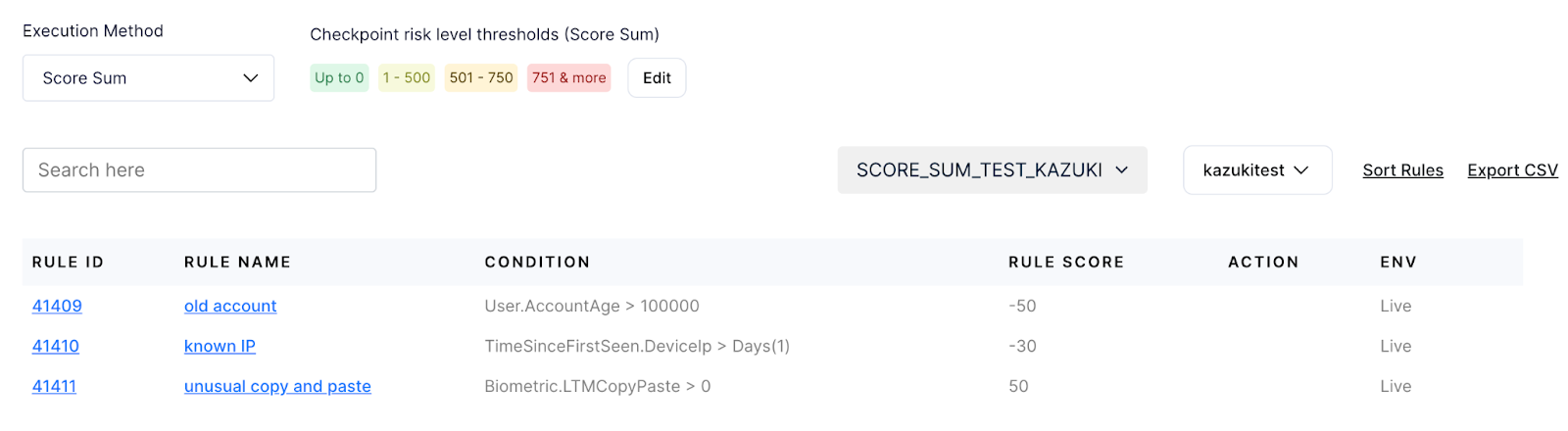
1. Score sum
Create a summary score from multiple rules. Sometimes, the fraud squad wants to combine evaluation results of multiple rules to add/subtracts points.
For instance:
- If the account is more than 90 days old, then subtract 20 risk points
- if there is a new IP address, then add 20 risk points
- if an unusual number of copies and pastes are present, add 50 risk points.
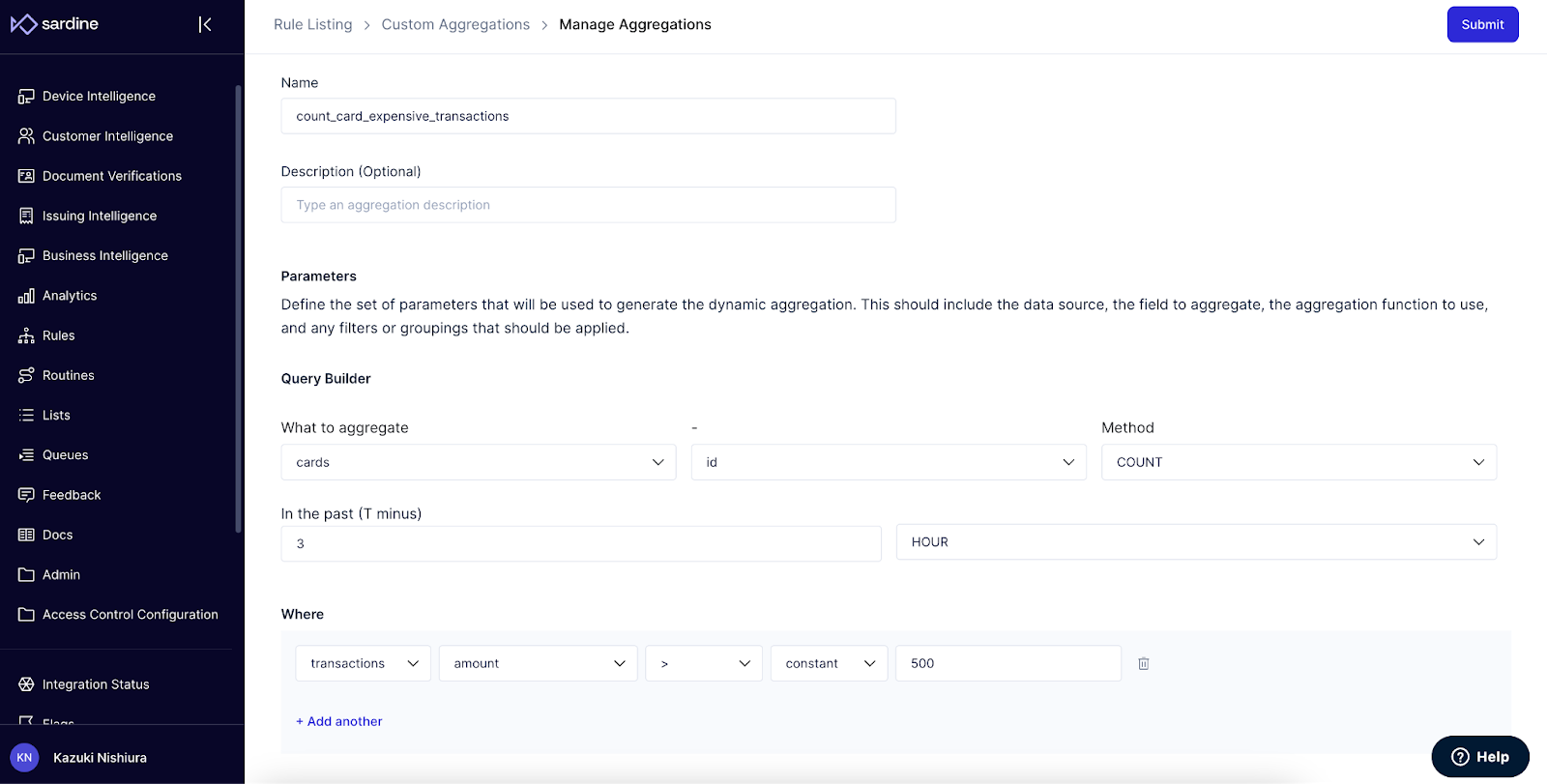
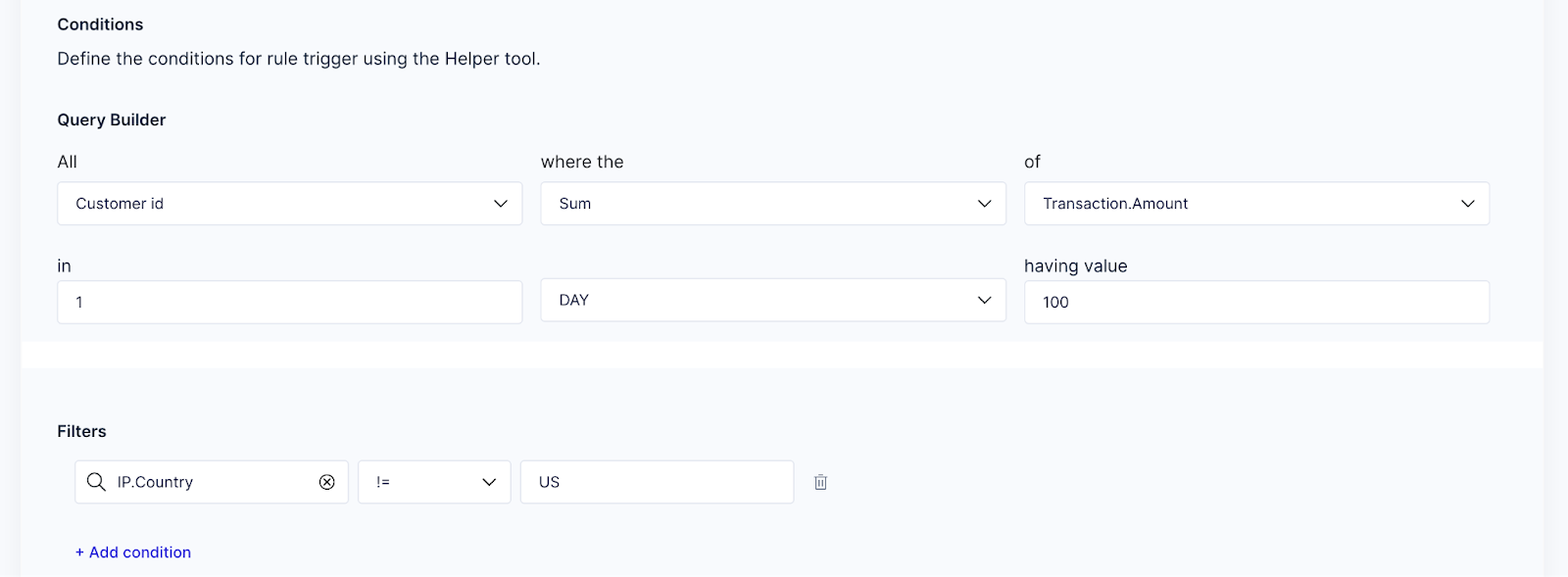
2. Custom aggregations
Imagine Sardine (or you) have the raw data you need, but the Sardine rules engine isn’t aggregating that to create the rule needed to detect this typology of fraud or risk. This is where custom aggregations come in allowing users to define their aggregations to fit their needs.
An example is below.
Defining what to aggregate (e.g. cards), with a method of aggregation (e.g. count) over a period (e.g. hours), and then a logical operation (e.g. where transaction amount is greater than 500).
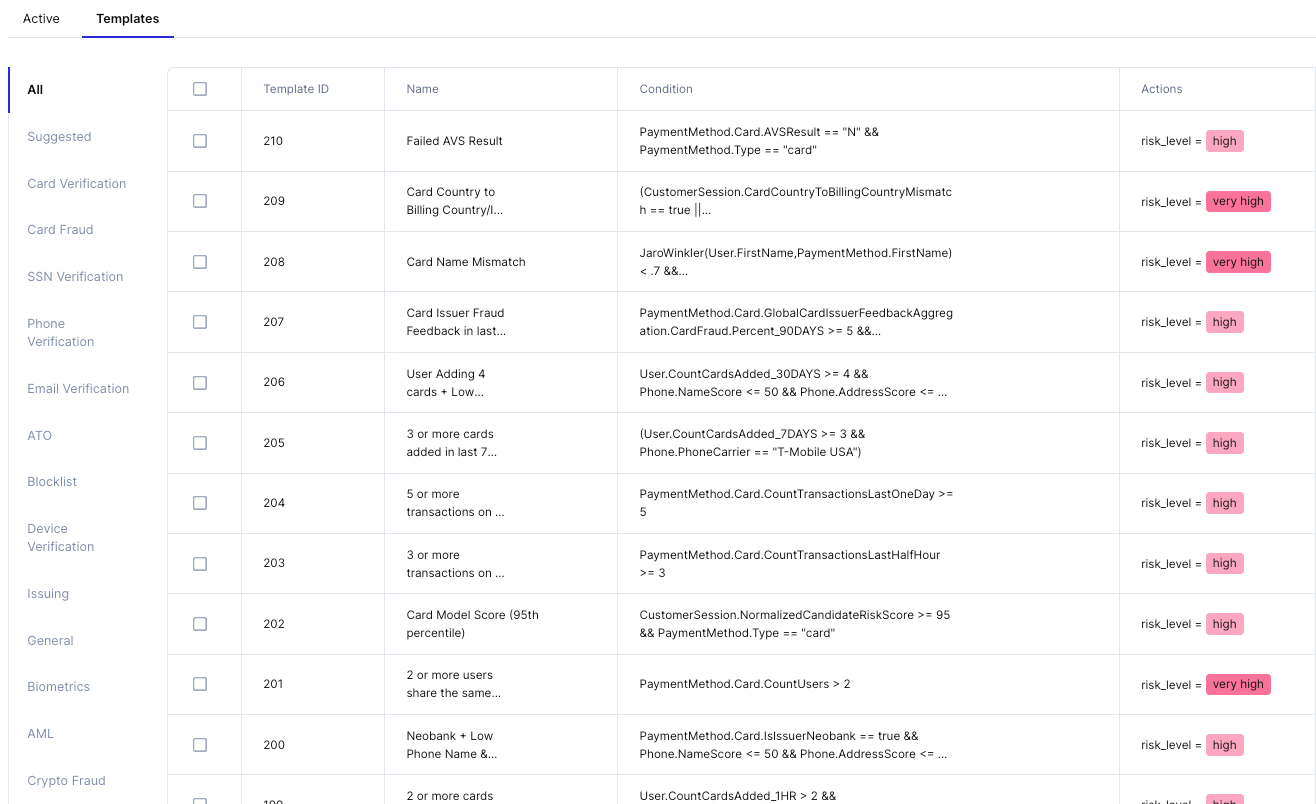
3. Rule templates
Being able to build anything is powerful, but often the hardest part is knowing where to start. At Sardine we can see data from our clients about what type of rule performs well in production.
We provide a rule template bank feature where customers can browse and import from a database of hundreds of tried and true rule templates
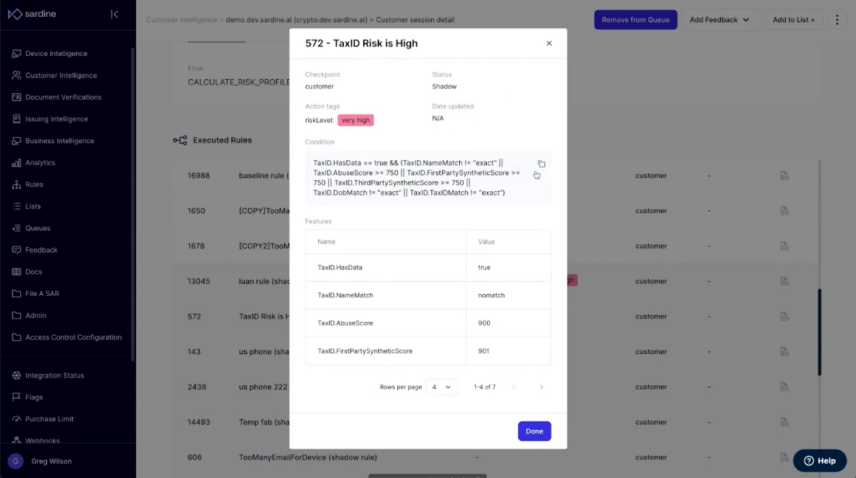
4. Rule revealer (recent hackathon project)
The fraud squad needs to know what rule fired and why when evaluating rule performance.
To reveal the why, for each rule, we display feature values and rule definitions at the time of the session, making it easier to conduct the investigation and audit whether the rules are working as intended.
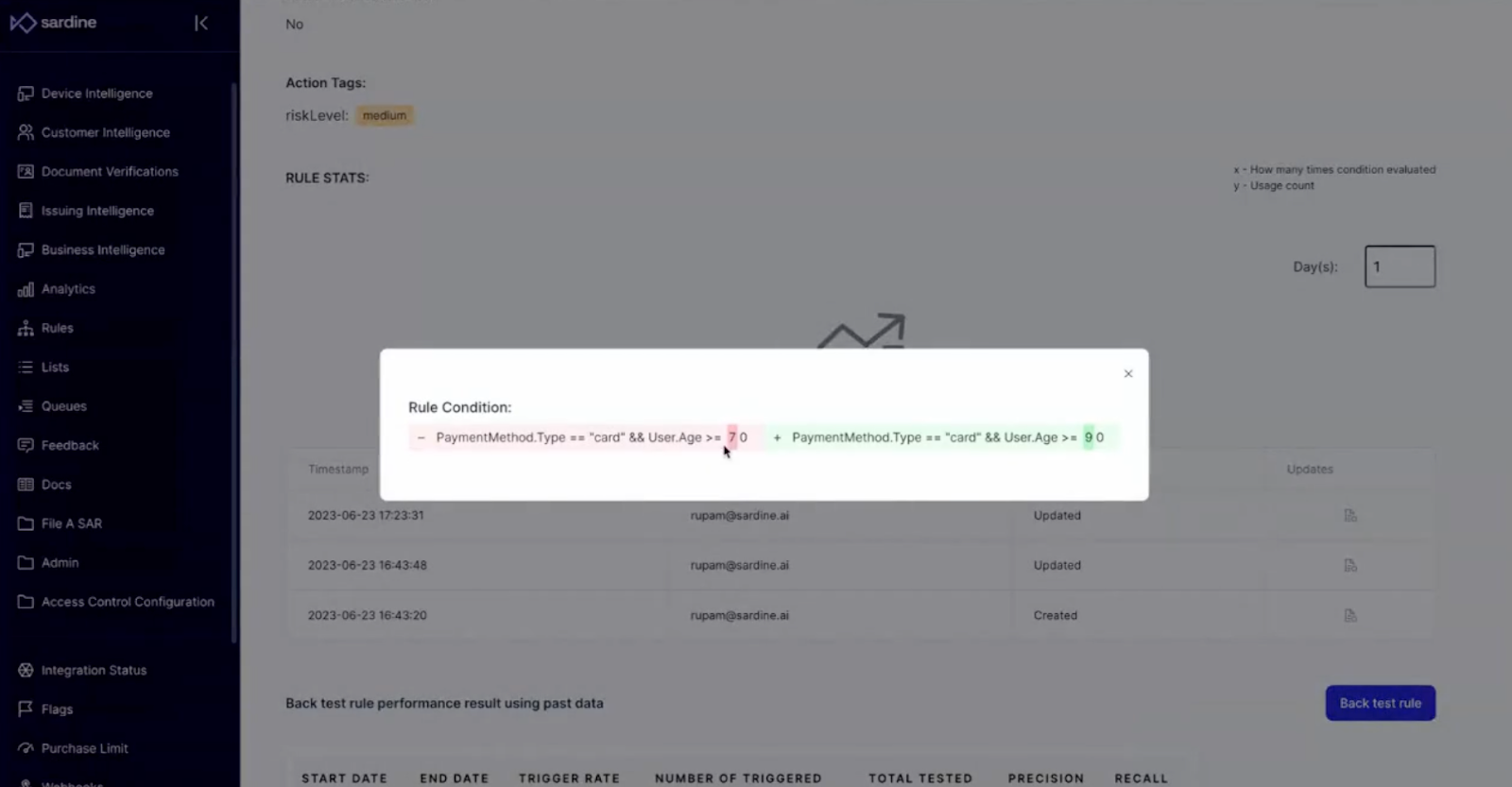
5. Rule changelog (recent hackathon project)
Rule misconfiguration can be expensive for the business, and it is important to have a historical audit log of the change history. For this reason, we built a UX for easily comparing before and after each change, along with the user who has changed it.
6. Routines (or batch rules)
By default our rules engine provides real-time rule logic evaluation with ~25ms latency, but there are some use cases that need to run daily, weekly, or monthly (e.g. a daily compliance review). For this, we built Routines, a capability to run custom SQL (through a SQL query builder or raw SQL) at a predetermined schedule (daily, weekly, monthly).
7. Custom variables (bring your own data)
Often a merchant or Fintech company already has data that is specific to their business requirements (eg, a user tier, or account history). For that reason, our rules engine can take any custom variables passed by our customers and use them in rules.
8. Analytics and Management Information (MI).
Our dashboard provides a wide range of analytics, including rule hit rates, precision, and recall.
However, sometimes, our clients want to do deeper analysis by joining our rule evaluation results with their own data. To make their lives easier, we also provide a data warehouse service that contains the entire context and history of rule evaluations.
9. Nested rules.
Most rule engines only offer AND as an operator. We offer both AND and OR inside a rule. We also allow for multiple nestings of AND and OR, so we can create more complex rules
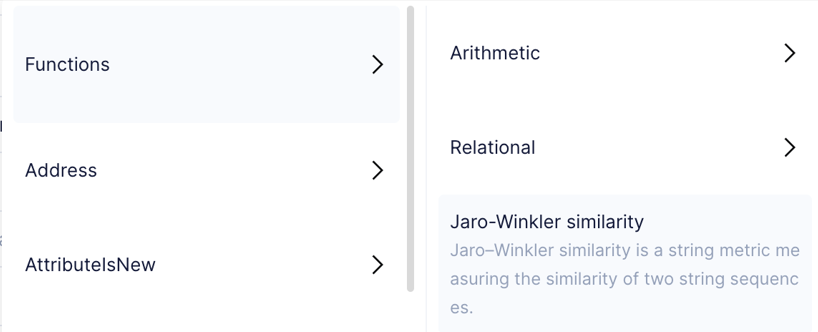
10. Advanced string queries like Jaro-Winkler.
Built in functions like "contains" or "not contains" can save hours of development or analyst effort. Advanced search capabilities like Jaro-Winkler that measures the similarity of two text strings are also available in the rules builder. Our most advanced users create incredibly sophisticated rule sets with the array of tools we provide.
4. Not all rules engines are created equal
Rules engines need to offer the maximum flexibility and power, while being simple to get started. As one enterprise client shared with us recently:

For us the Rules engine is just one piece of the fraud squad’s puzzle but its also a central one.
Not all rules engines are created equal, and the added flexibility of a warehouse, bring-your-own data, batch rules, scoresum, and shadow mode give fraud ops teams exactly what they need.
By the fraud squad.
For the fraud squad 🐟