



En la era de la IA, la infraestructura de fraude escala más rápido que los equipos de investigación.
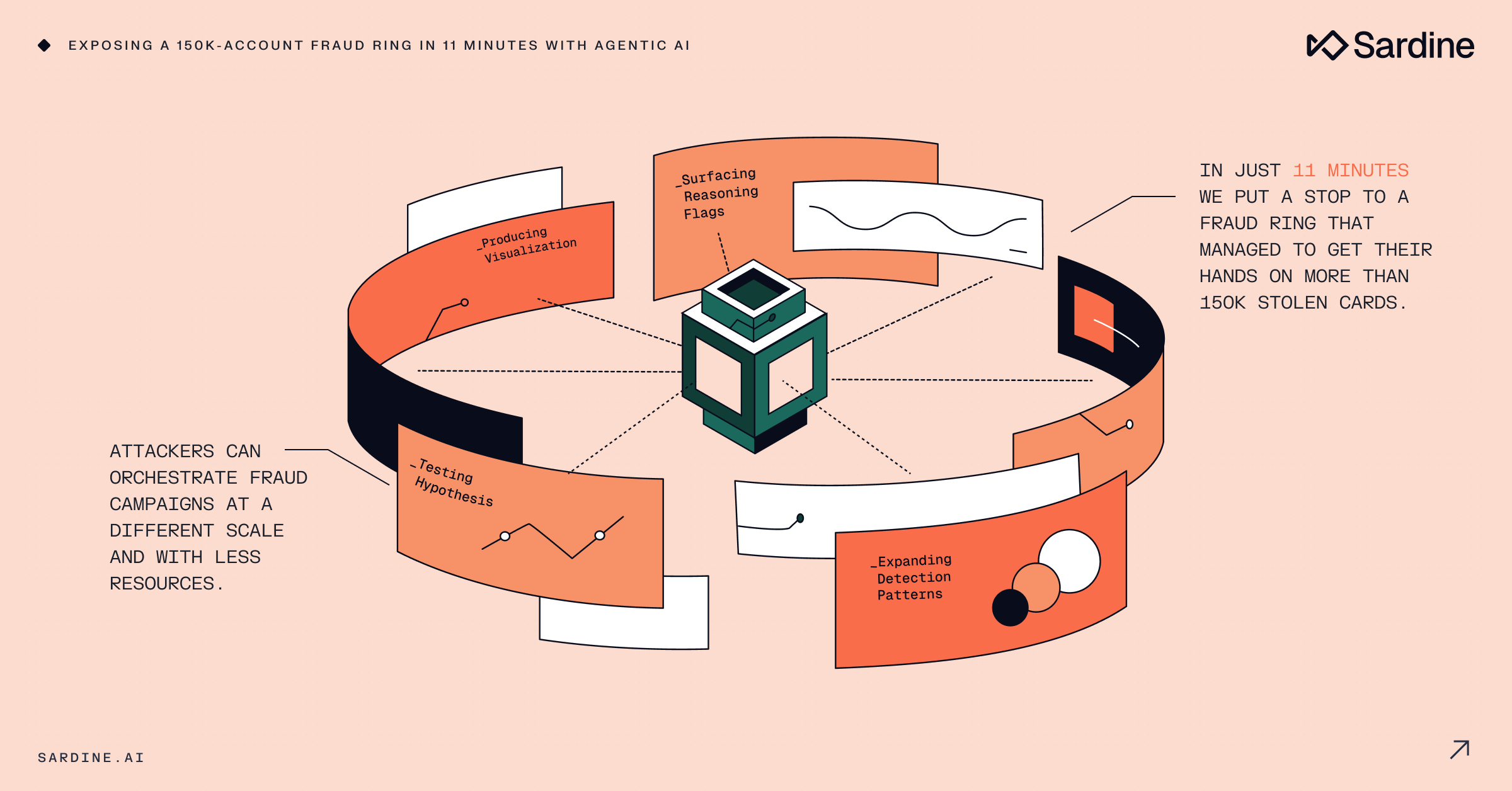
Los atacantes pueden orquestar campañas de fraude a otra escala y con menos recursos que en el pasado. La barrera de entrada para llevar a cabo estos ataques también ha caído drásticamente, ya que delincuentes sin experiencia ahora tienen acceso a capacidades con las que solo podían soñar hace apenas un año.
En uno de estos casos, uno de nuestros clientes sospechó que estaba siendo atacado. Los registros superaban las comprobaciones iniciales, pero algo no cuadraba. Varias cuentas parecían provenir de diferentes IDs de dispositivo, pero todas se correspondían con la misma huella subyacente.
Pero ahora, los equipos de lucha contra el fraude también se están preparando.
Cuando inicialmente nos llamaron para investigar, en lugar de exportar los datos manualmente y escribir una cadena de consultas SQL, le entregué la investigación a un Agente Analista de Datos que opera dentro de la plataforma de fraude de Sardine.
No para “decidir” nada, sino para recopilar, estructurar y poner a prueba las hipótesis con las que yo lo guiaba.
Lo que sigue es un desglose con marcas de tiempo de la investigación grabada en video.
La señal: reutilización de dispositivos y enmascaramiento de IP
La investigación comienza cuando un cliente de Sardine nos ha alertado de la sospecha de que está siendo atacado por una red de fraude. Estaban viendo múltiples registros desde diferentes ID de dispositivo, pero todos tenían la misma huella digital en la plataforma de Sardine.
Al analizar los casos individuales, también noté que la geolocalización por IP era engañosa. Cuando incorporé nuestra detección real de IP y la capacidad de atravesar proxies/VPN, el patrón se volvió muy evidente: aunque las cuentas estaban registradas en Estados Unidos, los estafadores en realidad se encontraban en Alemania y los Emiratos Árabes Unidos.
Si bien esto puede explicarse de forma individual, estaba muy claro que la combinación del uso masivo de huellas digitales de dispositivos y el enmascaramiento de la ubicación IP era incriminatoria: se trataba claramente de una única red de fraude.
Profundizamos en la mecánica de la toma de huellas digitales detrás de esto en nuestro análisis de la huella digital de dispositivos para la prevención del fraude y de los ATO.
Conclusiones clave
El ID de dispositivo es demasiado fácil de falsificar: Los estafadores pueden rotar los IDs de dispositivo, borrar las cookies y restablecer los entornos con facilidad. Lo que es más difícil de manipular es la huella digital subyacente del dispositivo. Si tu detección se basa solo en identificadores superficiales, pasarás por alto la reutilización coordinada.
Las señales en capas convierten los indicadores en patrones: Una sola huella digital es débil. Un solo desajuste geográfico es débil. Cuando la inteligencia de dispositivos enriquecida y la ubicación IP real se evalúan juntas, a través de múltiples cuentas, la señal se fortalece exponencialmente.
La infraestructura de fraude se vuelve visible a gran escala: El fraude a gran escala se optimiza para la reutilización, lo que obliga a los estafadores a exponer su infraestructura. Esto puede manifestarse como pruebas contundentes (diferentes ID de dispositivos aparecen como huellas digitales unificadas) o como vínculos difusos, como el hecho de que todas las IP enmascaradas provienen del mismo pequeño pueblo.
De las consultas a las hipótesis
No hace mucho tiempo, en este punto del proceso de investigación habría traducido mis hallazgos iniciales en una serie de consultas SQL y habría comenzado a hacer minería de datos.
Este proceso probablemente me habría llevado varias horas, sin contar el tiempo que me habría tomado familiarizarme con cómo se almacenan y estructuran los datos.
Pero SQL ya no es un requisito previo. Lo mismo ocurre con Python, R e incluso Excel: en su lugar, simplemente puedo compartir mi hipótesis con el agente y dejar que él haga todo el trabajo pesado.
Más que eso: en lugar de pensar en cómo escribir código, estoy pensando en las preguntas que quiero hacer.
Conclusiones clave
Los agentes con conocimiento de la plataforma superan a la automatización genérica: Fíjate en que no tuve que explicarle al agente qué significan las huellas digitales, las sesiones, los socios y las señales geográficas en el contexto de nuestra plataforma. Eso se debe a que lo entrenamos para entender el fraude y las primitivas del sistema. Ese contexto le permite poner a prueba hipótesis, no solo devolver filas.
Los agentes de IA seguros deben diseñarse para permitir la intervención humana: En lugar de pedirle al agente que me dé solo las conclusiones finales, le he indicado que también genere la gráfica con los datos representados. Esto me permitió hacer una rápida comprobación visual de coherencia sobre las conclusiones del agente.
Confirmación de hipótesis agentica
En respuesta, el agente produce un análisis en tres partes:
- Visualización de datos en bruto: ayuda a detectar rápidamente concentraciones, patrones o errores de análisis
- Resumen estructurado: resalta los hallazgos de acuerdo con mis indicaciones y el contexto
- Señales de razonamiento: llamar la atención sobre datos o conclusiones que se dejaron fuera del informe
En cuestión de segundos pude ver dos cosas. Primero, qué socios estaban más afectados y, segundo, qué socios tenían registros procedentes de la huella digital del dispositivo sospechoso únicamente. Estos socios o bien han sido vulnerados o, en el peor de los casos, están confabulados con los estafadores.
Conclusiones clave
El cuello de botella ya no es SQL: Los agentes de IA resuelven la mayor limitación en las investigaciones de fraude: poder acceder, consultar y analizar grandes volúmenes de datos. Los investigadores ya no están limitados por sus habilidades técnicas, sino solo por su capacidad para formular las preguntas adecuadas.
Los agentes guiados superan a las indicaciones abiertas: Fíjate que no le pregunté al agente “¿es esto fraude?” ni le di un lienzo en blanco para que especulara. Le di pistas específicas que debía validar: comprobar la concentración, evaluar la exposición de socios, medir la propensión a la reutilización. Un contexto acotado ayuda a que los agentes actúen como analistas estructurados que ejecutan hipótesis guiadas por humanos.
Los datos ignorados deben declararse: Los agentes deben, por supuesto, tomar decisiones basadas en el contexto a la hora de determinar qué datos incluir o qué conclusiones descartar. Eso es lo que los diferencia de las herramientas de automatización rígidas. Pero todos esos casos deben señalarse claramente al investigador humano para una verificación de coherencia.
Descubrir la infraestructura del fraude
Ahora que he confirmado mis sospechas iniciales, puedo usar los hallazgos revelados por el agente analista de datos para codificar el patrón que me interesa: huellas digitales de dispositivos de alto uso que también muestran una alta tasa de enmascaramiento de la ubicación IP.
Hasta ahora, he estado siguiendo las pistas que me dio el cliente, empezando por la huella digital del dispositivo sospechoso. Pero ahora que entiendo cómo opera la red de fraude, ya no estoy limitado a seguir una sola pista.
Con una simple indicación, puedo pedirle al agente que encuentre patrones similares. En cuestión de segundos amplié lo que parecía ser una red que afectaba a unos pocos miles de cuentas a una que abarca más de 150.000 entidades fraudulentas.
Este es el mismo enfoque basado en dispositivos y grafos que reveló 50.000 cuentas conectadas en un solo remitente, el cual explicamos en cómo la inteligencia de dispositivos expone las redes de lavado de dinero.
Conclusión clave
Defensa agéntica vs. ofensiva agéntica: Crear y dirigir una red de fraude que abarque a más de 150.000 personas requiere automatización, probablemente aprovechando agentes de IA. Para descubrir y combatir el fraude a esta escala y velocidad, los equipos antifraude también deben contar con capacidades agénticas.
De la información a la aplicación de la ley
Al concluir la investigación, ha llegado el momento de pasar a la acción. Antes de hacerlo, me aseguro de revisar manualmente algunos casos de otras huellas digitales de dispositivos recién detectadas y sospechosas.
Una vez que confirmo que presentan el mismo patrón (una IP de proxy en Londres, EE. UU., es una señal clara), procedo a añadir estas huellas digitales a nuestra lista de bloqueo.
Fuera de pantalla, también refuerzo las defensas del cliente con algunas reglas que están específicamente diseñadas para detener este anillo de fraude incluso si regresa con un nuevo conjunto de huellas digitales del dispositivo. Para ello, me centré principalmente en la velocidad de las huellas y en la discrepancia entre la ubicación real de la IP.
Conclusiones clave
Intervención humana en cada etapa: Antes de actuar sobre las nuevas huellas de dispositivos que había encontrado, volví a comprobar cuidadosamente las conclusiones del agente. Esto no es diferente de cómo actuaría si yo mismo hubiera ejecutado las consultas. Las comprobaciones de coherencia forman parte de cualquier proceso seguro.
Las investigaciones realizadas en la misma plataforma agilizan las acciones: La mayor ventaja de poder implementar soluciones en la misma plataforma en la que realizo las investigaciones es la coherencia. No hace falta averiguar cómo se denomina un dato concreto o, peor aún, descubrir que a tu motor de reglas le falta una función que utilizaste en tus consultas.
El futuro de las investigaciones de fraude
Como acabas de ver, en poco más de 11 minutos logramos detener una red de fraude que consiguió hacerse con más de 150.000 tarjetas robadas.
Mientras estaba terminando la investigación y detenía la grabación, había una pregunta en mi mente: ¿sería esto imposible si no tuviera acceso al Agente de Análisis de Datos?
Sinceramente, al menos al ver los resultados, lo dudo. Sí, podría haber pasado por alto algunas huellas dactilares si lo hubiera hecho yo mismo. Pero en general creo que lo habría resuelto de una forma similar.
¿El cambio real? Velocidad. Me tomó más tiempo documentar mis hallazgos y soluciones que hacer realmente el trabajo. Por mi cuenta, alcanzar los mismos resultados probablemente me habría llevado medio día de análisis. En el mejor de los casos.
¿Pero es este el caso para todo el mundo? Aquí va la incómoda verdad: soy un usuario privilegiado. No solo tengo acceso directo a los datos de Sardine, sino que también sé dónde encontrarlos y cómo analizarlos.
Y ahora, con el Agente de Análisis de Datos, este es el caso para cada usuario de Sardine.