
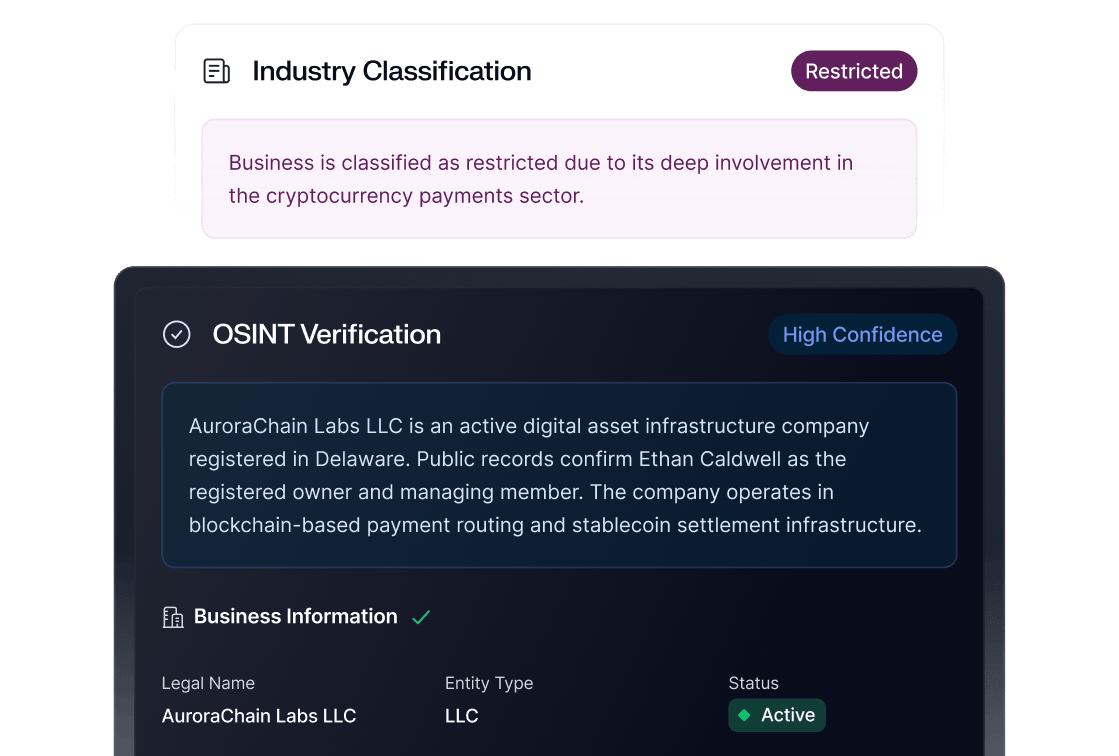





At Sardine we use protocol buffers (protobuf) everywhere. It is a lightweight and language-neutral serialization format with typing.
We use protobuf to define data schema of BigQuery table and also generate backend server (go) code from the same protobuf file. Our backend servers populates the golang struct (generated from protobuf), send it to pubsub, and then dataflow jobs pick them up in BigQuery.
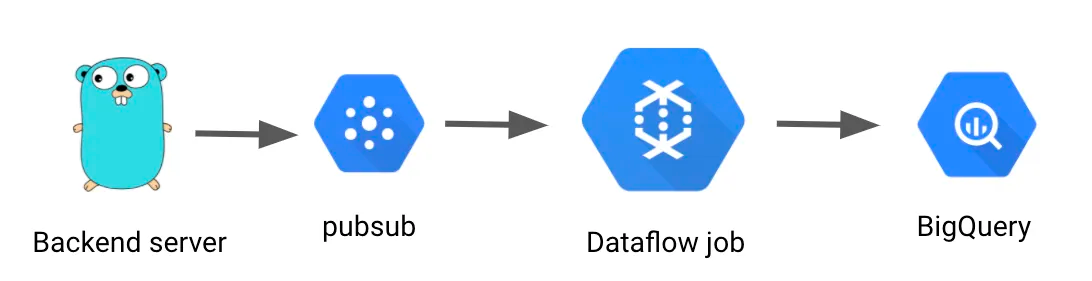
This simple pattern worked pretty well with one caveat. When we started, there was no clear solution on how to convert pubsub object to BigQuery row insert, so we needed to write boilderplate code like below to copy data from one object to another:
TableRow clientMetadataRow = new TableRow() .set("session_key", clientMetadata.getSessionKey()) .set("client_id", clientMetadata.getClientId()) .set("revision", clientMetadata.getRevision()) .set("user_id", clientMetadata.getUserId())...
This was very tedious and error prone. When we added a new field in bigquery table we needed to update the above boilderplate code too. There must be a better solution for this.
(side note — if you start a new service today, you could use JSON instead of protobuf as serialization format for pubsub, then use Google’s official pubsub-to-bigquery job template (beta) —https://cloud.google.com/dataflow/docs/guides/templates/provided-streaming)
It turns out that you can dynamically iterate protobuf object so instead of hard coding field names, we could do:
void copyFields(GeneratedMessageV3 fromProto, TableRow toRow) { allFields = fromProto.getDescriptorForType().getFields(); for (Descriptors.FieldDescriptor field: allFields) { Object value = fields.get(field); String columnName = field.getName(); switch (field.getJavaType()) { case STRING: if (value != null) { toRow.set(columnName, value); } break;...
That’s it! It reduced our boilerplate code and now we don’t need to worry about updating Java code (note you still need to redeploy dataflow job for any schema change so job runner knows about the latest proto definition)
We made the code public in below repo so the community don’t have to reinvent the wheel — https://github.com/sardine-ai/proto-to-bq-java
If you have any feedback, please reach out to me https://twitter.com/kazukinishiura
We’re hiring across all engineering roles — https://www.sardine.ai/careers