
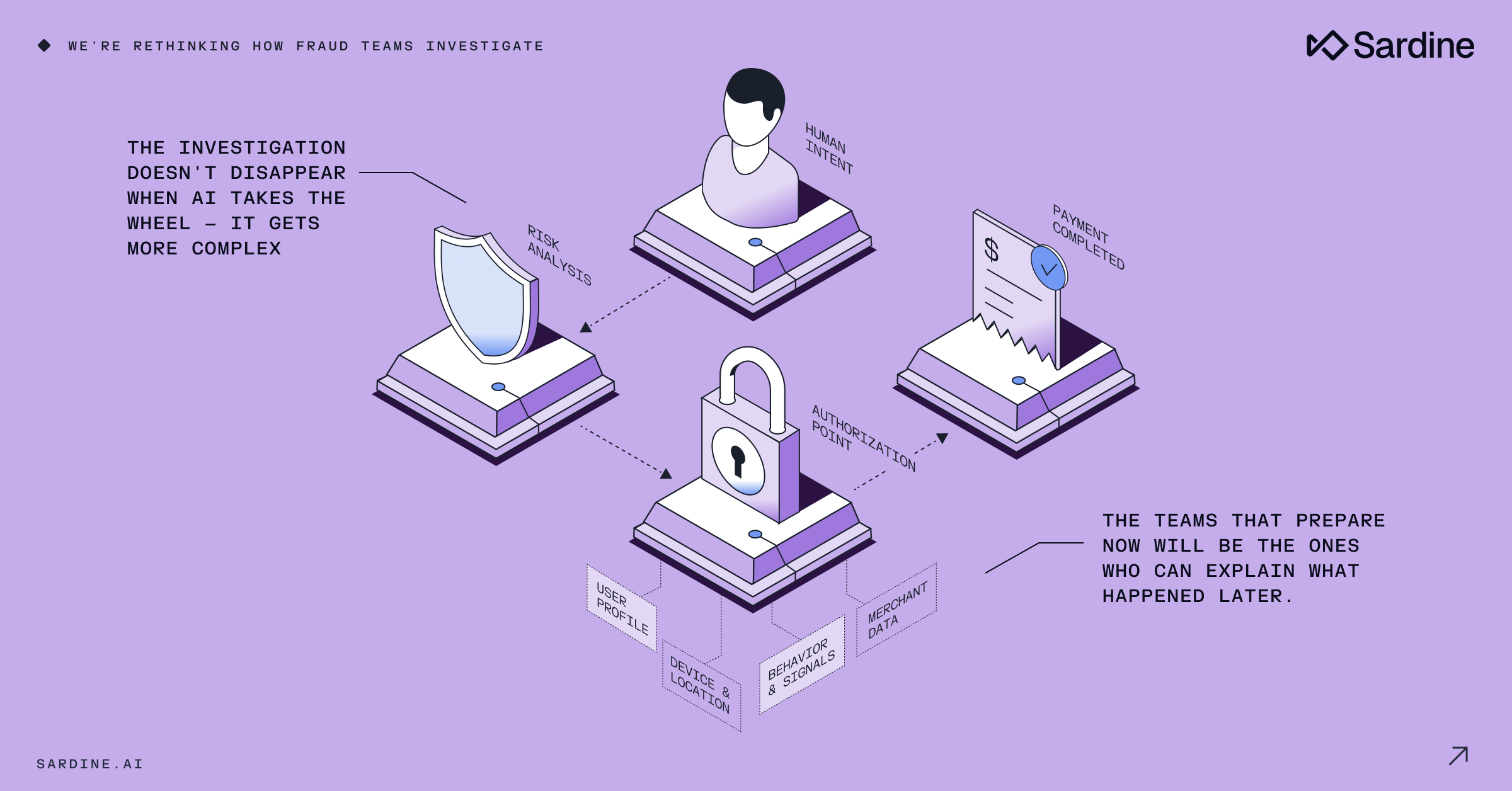



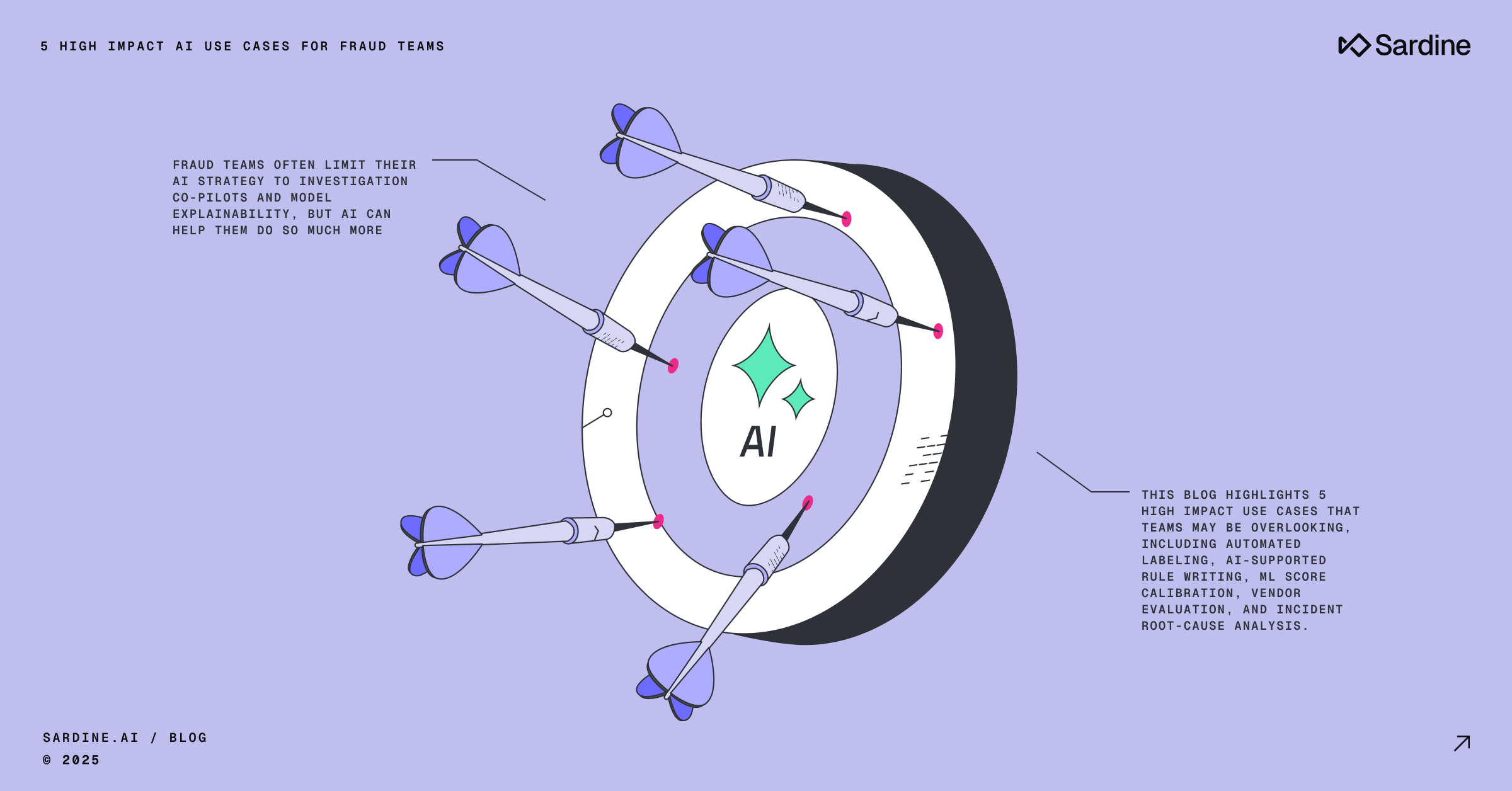
This post kicks off our 2026 Fraud Ops series, where we explore the practices that help fraud teams operate with greater accuracy, confidence, and speed. Over the coming weeks, I’ll break down the workflows, controls, and tools that separate reactive fraud programs from teams that are truly ready for 2026 and beyond.
The AI hype cycle is in full effect, and companies of all sizes are scrambling to find ways to leverage this new technology to supercharge their business.
I’m sure you’ve seen no shortage of LinkedIn posts and conference panels about all the ways that risk teams should be using AI. Yet for some reason, almost all the use cases center around copilots for investigations, alert handling, and ML explainability.
Don’t get me wrong. These are solid use cases (all of which Sardine supports). But if this is where your imagination stops, then you’re barely scratching the surface of what AI-powered fraud prevention can do for your fraud team!
If you’re a forward-thinking risk leader, here are five practical AI use cases for fraud teams that go well beyond the basics.
Using AI labeling for declined transactions
One of the trickiest challenges in fraud ops is labeling declined transactions correctly .
On one hand, it’s difficult to accurately identify false positives and optimize your system to avoid them in the future. On the other hand, it’s also difficult to correctly label real fraud attempts (the true positives) you managed to stop, while accurately measuring your performance.
This is an age-old challenge in the fraud prevention world and while there are different methods to approximate these labels, they never quite do the trick.
Grading common approaches to labeling declined events | ||||
Method | Accuracy | Scalability | Coverage | Effectiveness |
Chargeback data (delayed feedback) | High | High | Approved transactions | A |
Manual reviews (by investigators) | High | Low | Spot checks/samples, plus selected time windows | B |
Customer disputes (delayed labels) | Medium | Medium | Reported incidents only | C |
Strong links to known fraud cases | High | High | Approved and declined transactions | A |
This is a prime use case for LLMs to take over, as they can retain similar levels of accuracy as human investigators, but at scale. Even if you don’t trust an LLM co-pilot to make autonomous decisions without human intervention, this use case is different. Because you’re only labeling events that will be blocked anyway, you only use the output for monitoring and retraining your system. These tasks are also more “forgiving” to errors as they rely more on the “big picture” rather than individual labels, and do not trigger any customer-facing actions.
With a labeled “declined fraud” population, you can now tell if your new model candidate still blocks the same levels of fraud. You can also research rules or UX changes that would reduce the impact on legitimate customers.
Using AI as a rule recommendation engine
Different teams face different challenges when it comes to writing accurate and resilient fraud rules. Some teams can’t keep up with monitoring hundreds of rules and making sure the rules are optimized when they underperform. Some teams have trouble with writing accurate rules that don’t overload their system with false positives. And some teams don’t even know where to begin.
Regardless of the scale and skill level of your team, it’s highly likely that AI can reduce the friction you’re experiencing. While rules fire automatically in production, rule writing itself comprises many manual processes such as research, optimization, validation, monitoring, and logic updates. All of these can be streamlined, if not replaced completely, with AI agents. For example, in the video below you can see how Sardine’s Anomaly Detection is feeding an AI agent that recommends rules based on emerging suspicious patterns.
Humans can and probably should still remain in the loop. After all, these processes design solutions that make automated decisions that affect your customers. All LLM output should be observed and validated.
But the skillset and resources required to sanity-check the performance of a new rule are a fraction of what is needed to research and write it in the first place. Rules especially require an uncommon combination of both data literacy and domain expertise, and organizations that are missing one of them often struggle with rule writing. LLMs offer both of these, and for cheap.
Using AI to optimize ML scores
Any team that deals with Machine Learning models knows that it’s not a “plug-and-play” solution. To use it effectively, you need to analyze the ROC curve of the score performance and carefully pick the cutoff for your actions: above which score you’d want to block an event, flag for step-up investigation, or send to an authentication flow.
Choosing these cutoffs correctly can be quite a demanding data analysis task that not all teams are ready to take on, and not all vendors offer as part of their onboarding service. But even that is just scratching the surface.
Most ML scores, especially in complex businesses that span different regions, products, and payment methods, require even more care to avoid high false positive rates. It’s likely that each population segment across these dimensions will require a different cutoff.
In the figures below, you can see that by just overlaying two dimensions, regions and products, we now need to research nine different cutoffs just for the Block action.
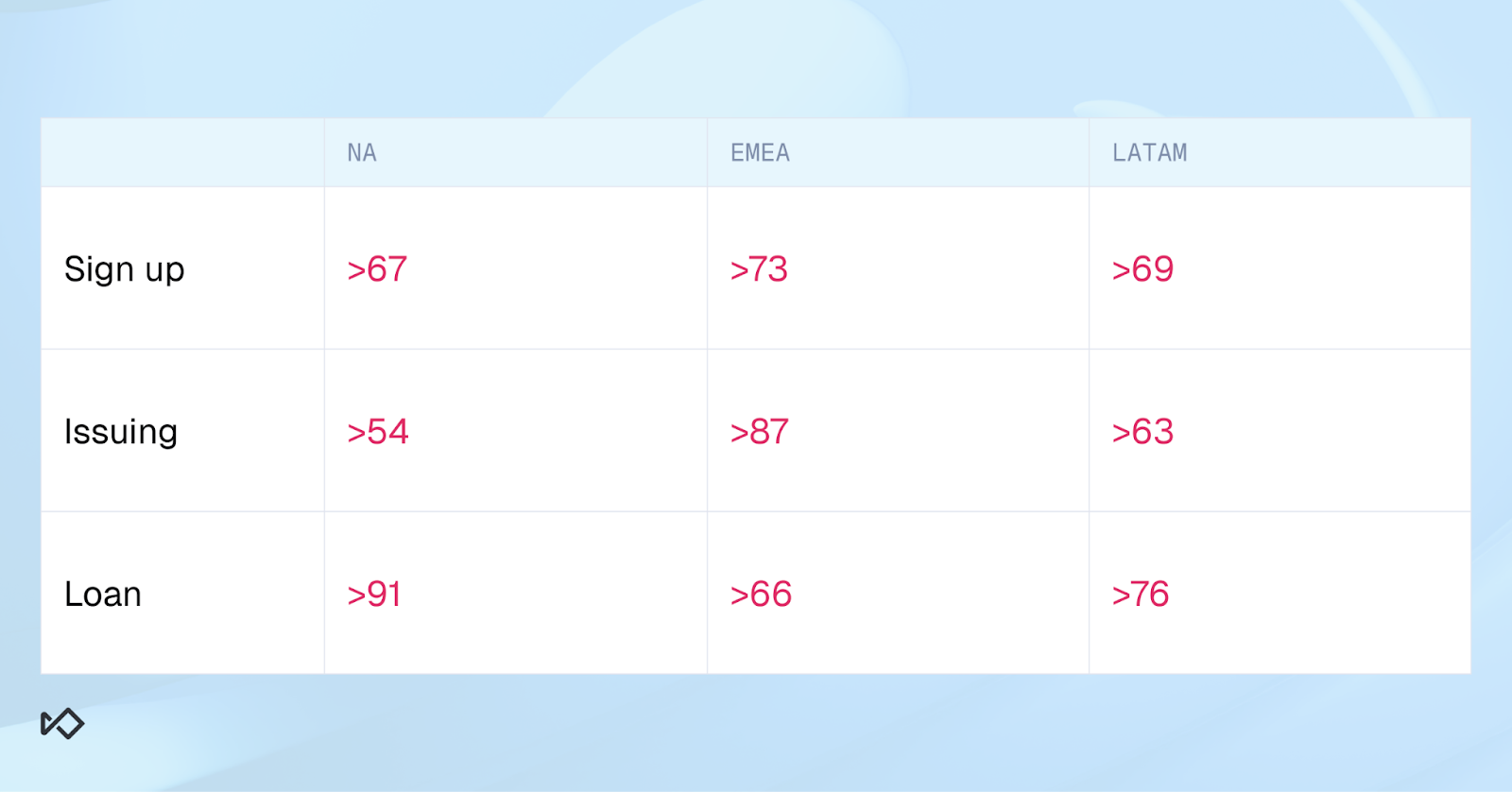
The reason we need to do that, and why the models themselves are not automatically calibrated to do it, is that each of these segments carries a different context. Different data quality and availability, different fraud pressure, different fraud patterns, and different fraudsters.
But the models are trained on the entire population, not on these individual segments. That’s where your fraud team comes into play in making these fine-tuning decisions.
Even the most proficient teams are hard pressed to invest this much effort into data analysis, so models often operate below their true potential. However, LLMs can support this use case in the same way they support rule recommendations. This not only saves time and resources, but for 9 out of 10 teams it would enable new heights of performance.
Using AI to avoid bias in vendor selection
Vendor selection is always a precarious decision, especially in risk management, where differences between the various players are often blurred by vague marketing. It’s a complex world that’s becoming even more so with the rise of sophisticated threats, and the new vendors that claim to solve these threats. Even an industry expert with many years in the field and a deep familiarity with its players would not know all the options.
But it’s not only about mapping out all the relevant providers. It’s also about shortlisting the ones that are truly relevant for your unique business. After all, each vendor specializes in different markets, industries, use cases, and customer sizes, even when they are selling the same thing as everyone else.
Teams often map out the options and weed out the irrelevant vendors in favor of what seems like an easy solution. Maybe one of the C-levels knows a guy who’s running a fraud solution, maybe you have joint board members, or maybe you’ll just pick the vendor your competitor uses. You just want to be done with it and move to the next task.

LLMs, and specifically AI agents, are a natural solution for this. An AI agent can interview you, distill your needs into a clear check list, research relevant vendors, and create a detailed shortlist in a manner of hours, if not less.
The point is not the time saved, but the confidence that your decision is based on proper market research that’s less likely to be biased by (often random) familiarity. And less bias means better long term results.
Using AI for incident root-cause analysis
One draining aspect of fraud prevention is constantly managing alerts, requests, and incidents. Changes in performance can happen daily and are influenced by a wide variety of internal and external factors such as code releases, product launches, seasonality, new or changing fraud patterns, and even marketing campaigns. Additionally, there are multiple metrics to watch, from losses and fraud rates to approval and conversion rates.
Because the types of incidents a risk team must evaluate are broad, it’s difficult to foresee which scenarios can manifest themselves, and in turn codify an automated response. This means that as incidents happen daily, the risk team is left to manage them mostly manually, from screening dashboards during the morning standup, through root-cause analysis, and on to timely resolution. And while the team is swarming to solve an issue, its goals for that week are left disrupted.
When you consider the many possible root-causes, the process becomes even more difficult. Finding out whether the new model version is misbehaving will require you to look in one place, while figuring out if this isn’t just a seasonality issue means looking in another. Unless you have a very accurate guess to start with, it’s possible to go through more than five different analysis exercises before you figure out who’s the culprit. Once more, these challenges are more pronounced in teams that lack experience or data literacy.
Agentic AI can bridge this gap because it doesn’t rely on a pre-defined set of scenarios it must monitor.
Before / After root-cause workflow | |
Manual incident analysis today | AI-assisted root-cause analysis |
Scan dashboards during morning standup | Detect anomalies automatically across metrics |
Form and test one hypothesis at a time | Propose multiple ranked hypotheses simultaneously |
Jump between rules, models, logs, and traffic reports | Pull relevant signals into a single investigation view |
Rely heavily on analyst intuition and prior experience | Prioritize hypotheses based on observed data changes |
Time-to-resolution varies by analyst and incident | Reduce time-to-resolution by narrowing the search space faster |
A framework for when to use AI
AI is only starting to make waves in risk management, and the use cases to explore are many. The five ideas shared above are just examples designed to jumpstart your imagination. Hopefully they got you thinking.
But what if you’re facing other challenges in your day-to-day work? Which of them are a good fit for LLMs? How do you make sure there are no proven solutions already in place before you start experimenting?
If this is the case, consider a few characteristics of problems where GenAI can come in handy:
- Dealing with unstructured data
- Decision scenarios that are too fragmented to automate
- Data analysis requirements that are beyond your team’s current setup
If a problem answers at least two of the above, it’s likely that LLMs would be useful in providing a solution with very little resources.
Stay tuned for the next blog in our Fraud Ops 2026 series: How to Release Fraud Rules Safely.