


En la parte 2 de nuestra serie sobre el auge de las Operaciones de Fraude Agénticas, Chen Zamir presenta la secuencia de cinco pasos para entregar tu ciclo de reacción al fraude a agentes de IA y explica por qué el orden es tan importante como los propios pasos.Ponte al día con la parte 1 aquí.
La mayoría de los equipos de fraude que han empezado a usar IA agéntica comenzaron en el lugar correcto. Están probando agentes dentro del proceso de investigación: enriqueciendo alertas, estructurando casos y proponiendo resoluciones para que los investigadores las validen. En general, están viendo claras mejoras de eficiencia gracias a ello.
El problema es que casi nadie está yendo más allá.
En una entrada anterior, sostuve que el KPI principal en fraude no es la precisión ni la exactitud. Es el ciclo de reacción: el tiempo que tarda tu sistema en detectar una brecha y enviar una solución para corregirla.
Y aunque los estafadores están utilizando IA para adaptarse más rápido, los equipos de fraude deberían usar IA agéntica para igualar esa velocidad.
Automatizar partes de tu proceso de investigación es solo el primer paso en ese camino.
Comprimir ese único paso mientras los otros cuatro siguen funcionando a velocidad humana te da una función de investigación más rápida, pero con el mismo ciclo roto. Las reglas que tus investigadores persiguen siguen deteriorándose. Las etiquetas que alimentan tus modelos siguen llegando con semanas de retraso.
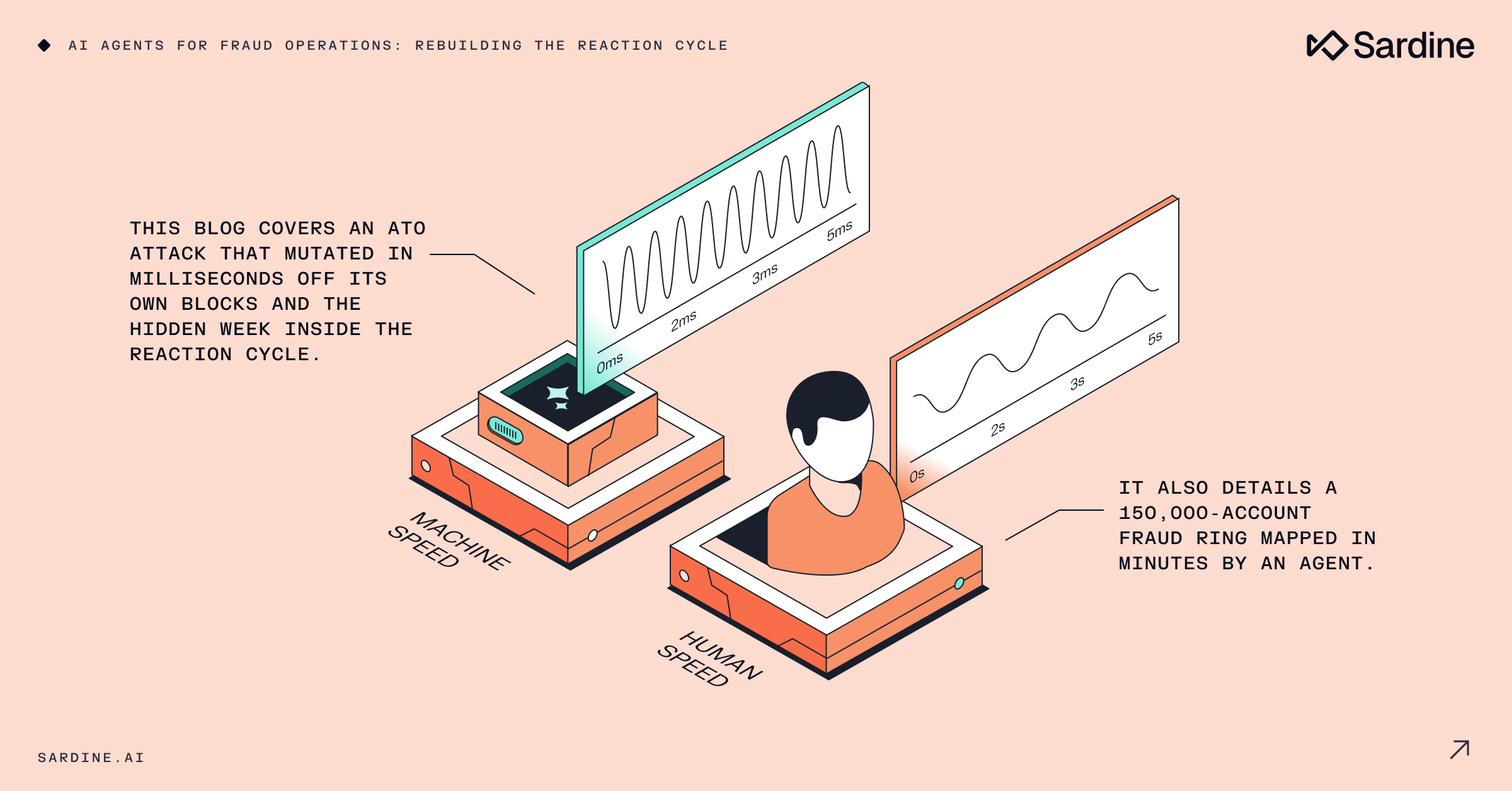
Pero cuando todo el ciclo se ejecuta a velocidad de máquina, el sistema se convierte en algo diferente. Las decisiones se toman a nivel de población y de anillo en lugar de una por evento.Una sola investigación etiqueta 150.000 cuentas. Una propuesta de política sustituye a decenas de revisiones manuales. El coste por decisión se reduce en un orden de magnitud.
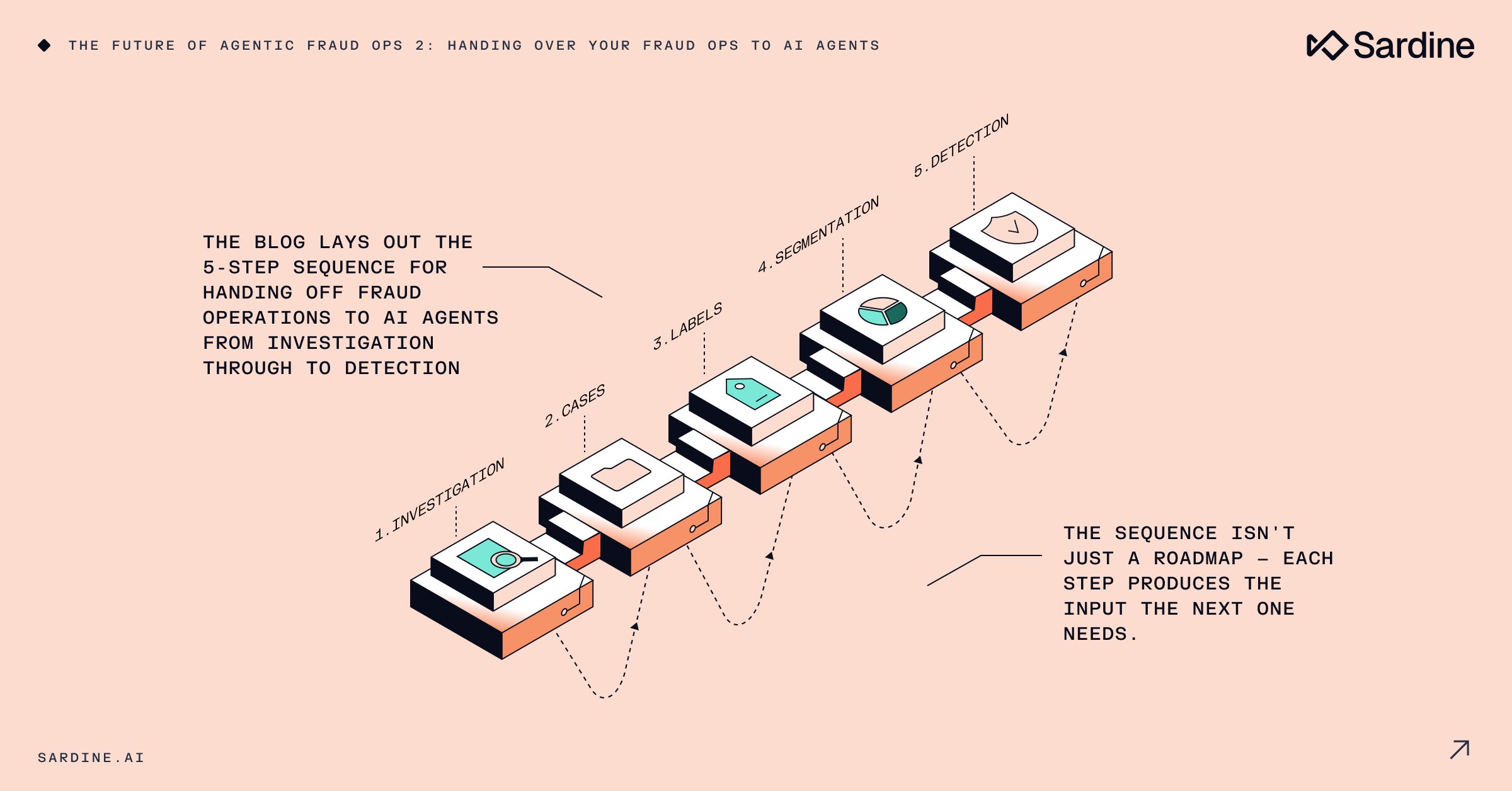
Llegar allí requiere cinco pasos, y el orden importa más de lo que la mayoría de los líderes de fraude esperan. Cada paso genera un insumo que el siguiente necesita, o desarrolla la capacidad que el equipo necesita para gobernarlo.
Si te adelantas, terminas con automatización de reglas basada en etiquetas obsoletas, automatización de políticas que nadie sabe cómo gobernar y un año de presupuesto gastado en sistemas que no generaron efectos compuestos.
La secuencia que quieres seguir es esta:
- Investigación: enriquecer alertas, estructurar casos, proponer resoluciones
- Casos: agrupar alertas relacionadas en casos a nivel de anillo
- Etiquetas: generar señal de entrenamiento de forma continua
- Segmentación: automatizar las políticas de tratamiento de la población
- Detección: automatizar propuestas de reglas y modelos
Lo que sigue recorre cada paso y explica por qué aparece donde lo hace.

Por dónde empezar: Investigación de fraude con agentes
Aquí es donde la IA agéntica está hoy más madura, donde probablemente se concentra la experiencia de tu equipo y donde los ahorros se hacen visibles primero. En concreto, quieres abarcar tres áreas:
Enriquecimiento pasa del investigador al agente. Los 15 minutos de recopilación de datos del dispositivo, contexto de IP, historial de la cuenta y consultas externas se realizan en paralelo y se adjuntan al caso antes de que el investigador lo abra.
Resultado del caso se vuelve estructurado. En lugar de párrafos escritos en un campo de comentarios que nada más puede leer, los casos se registran en un formato coherente y legible por máquina. Esta es la parte que más importa para todo lo que viene después.
Y por último, el agente propone resoluciones con su razonamiento. El papel del investigador pasa de generar la llamada a validarla. Esa es una habilidad nueva, y este es el entorno de menor riesgo para que tu equipo comience a desarrollarla.
El beneficio en eficiencia es real: una investigación de 30 minutos se reduce a unos cinco. El beneficio más profundo es que los resultados de la investigación están mejor estructurados, estandarizados y son legibles por máquina.
Luego crea casos a partir de las alertas
Una vez que los casos están estructurados, los agentes de IA pueden empezar a agruparlos. Las nuevas alertas se comparan con casos conocidos (anillos de fraude) a medida que llegan, según la huella digital del dispositivo, el patrón de financiación o la firma de comportamiento. Las coincidencias se atribuyen al caso existente. Las que no coinciden se convierten en candidatas para uno nuevo.
La cola del investigador deja de ser un montón de alertas inconexas y se convierte en un conjunto seleccionado de casos consolidados. La expansión de los anillos ocurre automáticamente y libera la verdadera eficiencia de tu equipo, ya que una sola decisión ahora etiqueta miles de eventos a la vez.
Este paso es imposible sin el trabajo de estructuración previo. Los equipos que lo omitieron no pueden crear agrupamientos en absoluto.
Luego automatiza las etiquetas de detección de fraude
Hasta ahora puede que hayas ganado en eficiencia, pero tu ciclo de reacción no es significativamente más rápido. Este paso es el requisito previo que lo cambia todo, y no puedo enfatizar lo suficiente lo importante que es.
El mayor cuello de botella en tu ciclo de reacción son las etiquetas. Los contracargos llegan semanas después de la transacción, a veces meses, y para cuando has confirmado la verdad sobre lo ocurrido, el patrón de ataque ya ha cambiado.
He visto equipos con sistemas de detección de última generación que aun así rinden por debajo de lo esperado por una razón: su ciclo de retroalimentación era simplemente demasiado lento.
Con una IA agente y siguiendo los pasos en el orden correcto, puedes cerrar esta brecha con relativa facilidad. Ya cuentas con un agente de IA que propone resultados de las investigaciones, y esas recomendaciones pueden convertirse en etiquetas a gran escala.
La razón por la que esto funciona es que las etiquetas para el entrenamiento no tienen que ser perfectas. A ningún cliente se le rechaza porque un analista haya etiquetado su transacción como sospechosa. Las etiquetas solo se utilizan para volver a entrenar los modelos y hacer backtests de reglas, no para decisiones de cara al cliente.
¿Podrían las etiquetas imperfectas asignadas incorrectamente por los agentes debilitar tus decisiones? En realidad no, porque las reglas y los modelos de ML ya funcionan con datos ruidosos. Una tasa de error moderada por parte de un agente no es peor que el ruido que ya tienes en los contracargos y en las resoluciones de las investigaciones. Y esa tolerancia a la imperfección es lo que hace posible el etiquetado continuo a gran escala.
Al final de este paso, la parte más lenta de tu ciclo de reacción habrá pasado de semanas a horas. Es entonces cuando se abren las verdaderas posibilidades.
Luego aborda la segmentación del riesgo
La segmentación es la capa que decide cómo procesarás y evaluarás el riesgo de cada evento: qué reglas se activan, qué proveedores son llamados o si se desencadena una autenticación reforzada.
Muchos equipos tienden a ignorar este paso crucial, y hasta aquellos que no lo hacen suelen recurrir a prácticas de configurar y olvidar. Pero esa es la capa en la que implementas tu estrategia contra el fraude, y pasarla por alto ralentiza tu capacidad de reaccionar ante amenazas emergentes.
Una advertencia: es probable que la segmentación aún no tenga un responsable definido, objetivos, KPIs ni un proceso para mover poblaciones entre segmentos.
El asunto es que simplemente no puedes automatizar algo que nadie está gestionando manualmente primero. El equipo tiene que aprender cómo es un buen funcionamiento antes de poder supervisar a un agente que proponga cambios.
Hay otra diferencia que vale la pena señalar: este es un movimiento nuevo para tu equipo. Los pasos anteriores siguieron el mismo patrón, en el que el agente observa el flujo de datos en producción y procesa lo que pasa por él.
Pero recomendar un cambio en tu segmentación de riesgo funciona de manera diferente. El agente analiza el desempeño histórico de los tratamientos en distintas poblaciones y propone cambios de política, no decisiones sobre casos individuales. Esto no es solo una cuestión de semántica, cambia la forma en que pruebas, validas y supervisas las decisiones del agente.
La buena noticia es que el agente no está creando nuevos segmentos; está moviendo poblaciones entre los ya existentes. Por ejemplo, un grupo de cuentas de 25 a 30 días de antigüedad pasa del segmento de alto riesgo al de riesgo medio porque su comportamiento se parece al de los usuarios consolidados.
Dado que los segmentos de riesgo son conocidos y están acotados, es más fácil probarlos y validarlos que crear nuevas reglas de detección de fraude.
Deja la capa de detección para el final
La detección es la capa que clasifica los eventos. Los modelos de ML puntúan, las reglas se aplican por encima y, juntos, manejan la mayoría de las decisiones de forma automática. Pero no debemos confundir la ejecución automática de reglas con la creación automática de reglas.
Automatizar la detección al final es la decisión correcta, por dos razones.
La primera razón ya la hemos tratado: el combustible. La automatización de la detección necesita etiquetas nuevas y confiables para ser útil. Sin un sistema de etiquetado temprano y automatizado ya en funcionamiento, un agente que propone nuevas reglas solo está proponiendo reglas equivocadas más rápido.
La segunda razón: gobernar agentes que crean y ajustan reglas es complejo, especialmente si tu equipo aún no ha desarrollado la habilidad de escribir reglas por sí mismo o de gestionar agentes que realizan análisis de datos en profundidad.
A diferencia de la segmentación, donde el agente elige entre opciones existentes, la detección es generativa. Propone cosas que antes no existían: nuevos patrones de reglas, nuevas características y posiblemente nuevos modelos de aprendizaje automático.
Dominar la segmentación agéntica brinda a tu equipo la experiencia de gobernanza que la automatización de detección requiere.
Pero una vez que has dominado este paso, tu ciclo de reacción funciona a velocidad de máquina. Las alertas llegan, se agrupan en casos a nivel de anillo, se etiquetan automáticamente y alimentan a los agentes que ejecutan análisis continuos para detectar cambios de segmento y nuevas recomendaciones de reglas.
Lo que realmente se necesita
Seamos honestos, este no es un proyecto de un solo trimestre.
Los equipos más avanzados llevan entre seis y doce meses en este proceso y dirían que aún tienen trabajo importante por delante. Cada paso requiere herramientas, cambios organizativos y tiempo para que el equipo asimile una nueva forma de trabajar antes de que el siguiente paso tenga sentido.
Los equipos de fraude se enfrentan a un riesgo claro aquí. Por un lado, la presión para adoptar la IA y reducir el personal aumenta día a día, pero hay muy poca claridad sobre cómo hacerlo de forma segura.
En un entorno incierto, es fundamental entender cuál es tu objetivo final: no solo reducir costos, sino construir una organización mejor. Una vez que sabes lo que eso significa para tu negocio, la secuencia adecuada se vuelve evidente.
Como expliqué, la secuencia no se trata solo de dónde puedes recortar más costos. También se trata de eliminar dependencias y desarrollar nuevas capacidades en el equipo. Si ignoras esto, puede que tengas que volver a contratar apresuradamente al equipo que pensabas que era redundante. Y todos sabemos que no es tan sencillo.
Obtén la imagen completa
Este es un resumen de la hoja de ruta. Para tener una visión completa, consulta el whitepaper en el que se basa esta publicación.
Explica por qué las operaciones de fraude con agentes son una realidad para la que todos los equipos de fraude deben prepararse, cómo debería ser un sistema de este tipo, la dotación de personal y la combinación de habilidades que realmente necesita, el modelo de gobernanza que mantiene el aprendizaje continuo seguro a escala y los patrones de implementación a 18 meses: qué funciona, dónde los equipos lo rompen y cómo defender la secuencia dentro de tu organización.
Si eres la persona en tu empresa que va a financiar, planificar y defender este trabajo internamente, allí encontrarás muchas de las respuestas.
Cuando evalúes plataformas para esta secuencia, pide a los proveedores que te den su respuesta a cinco preguntas, en este orden. ¿Cómo verifican la identidad del agente? ¿Cómo infieren la intención del agente? ¿Cómo miden el comportamiento frente a los patrones esperados? ¿Cómo autorizan acciones específicas y las revocan? ¿Cómo supervisan continuamente las sesiones a lo largo del recorrido del usuario?
Los proveedores que tienen respuestas a las cinco preguntas operan con un modelo de confianza completo. Los que solo pueden responder a dos o tres aún lo están construyendo.