


The Saturday Fraud Strategist
Clase magistral sobre falsos positivos, parte 1: Cómo medir los FPs en sistemas que los ocultan
Honestamente, la mayoría de los equipos de fraude no tienen idea de cuántos buenos usuarios están bloqueando realmente.
Si le pides a alguien sus datos de contracargos, normalmente obtendrás una respuesta muy precisa. Pero si preguntas cuántos clientes legítimos fueron rechazados por error, de repente las cosas se vuelven mucho menos científicas.
Normalmente, algo entre un encogimiento de hombros y un “probablemente no muchos”.
No es una buena señal.
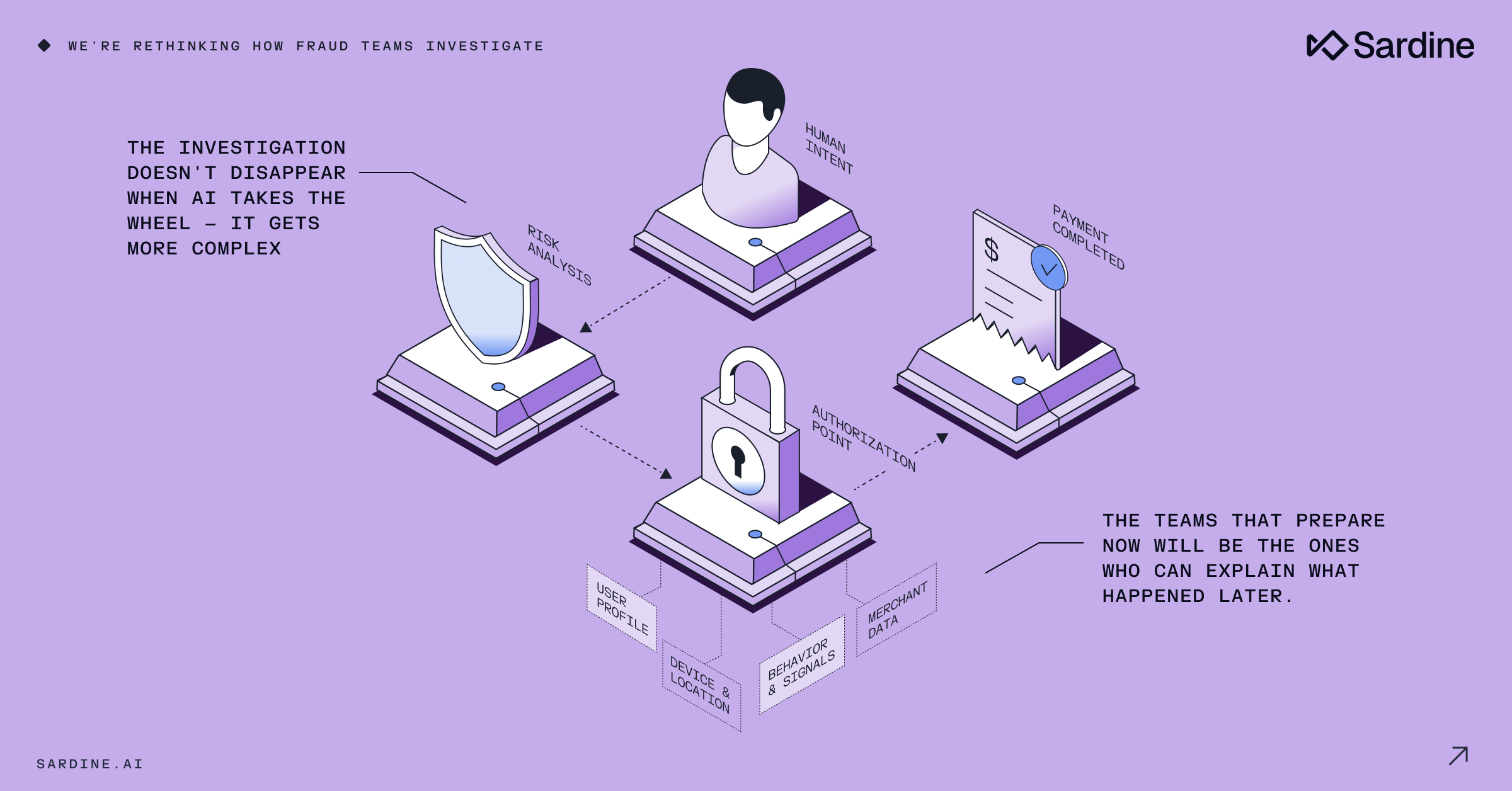
La detección de falsos positivos de fraude es fundamentalmente difícil, no porque a los equipos de fraude no les importe, sino porque los sistemas antifraude suelen estar diseñados de manera que los falsos positivos sean invisibles por defecto.
Si apruebas una transacción, el sistema recibe retroalimentación. El fraude se convierte en contracargos. Los usuarios legítimos regresan y vuelven a realizar transacciones.
Pero cuando bloqueas a alguien, la señal desaparece.
La queja queda enterrada en una cola de soporte. El cliente nunca vuelve a intentarlo. El evento nunca llega a convertirse en una etiqueta. Y de repente, tu canal de análisis de fraude ni siquiera se entera de que el error ocurrió.
Ese es realmente el problema central que explora este episodio.
Más específicamente, cómo los equipos de fraude pueden empezar a medir las tasas de falsos positivos utilizando enfoques imperfectos pero prácticos, como la simulación de reglas de fraude, la revisión manual, la resolución de entidades, los grupos de control, la monitorización de transacciones y la retroalimentación de los usuarios.
Antes de poder reducir los falsos positivos, primero debes demostrar que existen.
Lo que escucharás en este episodio:
- Por qué la detección de fraude con falsos positivos es difícil en sistemas basados en bucles de retroalimentación incompletos
- Cómo las transacciones rechazadas desaparecen de los análisis de fraude y de los datos de entrenamiento de modelos
- Por qué los datos de contracargos son más fáciles de medir que los usuarios legítimos bloqueados
- Un desglose de la simulación de reglas contra el fraude y de dónde falla operativamente la simulación
- Cómo la revisión manual ayuda a identificar falsos positivos ocultos en los sistemas de detección de fraude en pagos
- Por qué la resolución de entidades se convierte en una de las herramientas más potentes para vincular a los usuarios bloqueados con comportamientos legítimos posteriores
- Cómo los grupos de control revelan debilidades ocultas en los sistemas de toma de decisiones contra el fraude
- Dónde los bucles de retroalimentación de los usuarios pueden ayudar y dónde se vuelven peligrosos
- Por qué la estrategia de prevención del fraude depende de comprender la reducción de falsos positivos a nivel operativo
- Cómo cambia la gestión del riesgo de fraude una vez que los equipos entienden de dónde provienen realmente los falsos positivos
Una conversación sobre sistemas de fraude, errores ocultos, puntos ciegos operativos y por qué medir los falsos positivos es en gran medida un ejercicio de triangulación más que de certeza.
Quién debería escuchar:
- Líderes de fraude y analistas de fraude
- Equipos de riesgo y cumplimiento
- Responsables de operaciones de fraude
- Equipos de prevención de fraude en FinTech
- Profesionales en detección de fraude de pagos
- Equipos que gestionan sistemas de toma de decisiones contra el fraude
- Equipos de ciencia de datos y análisis de fraude
- Cualquier persona responsable de la supervisión de transacciones, las herramientas de prevención de fraude o la reducción de falsos positivos
Básicamente, si alguna vez has mirado tu sistema de fraude y te has preguntado si estás bloqueando a más usuarios legítimos de los que crees, este episodio es para ti.
Notas del episodio
Visibilidad
Los sistemas antifraude son muy buenos para medir el fraude confirmado. Son mucho peores para medir a los clientes legítimos que desaparecen después de ser bloqueados.
Y eso genera un problema operativo extraño: los equipos de fraude suelen optimizar en función de lo que pueden ver, mientras ignoran las pérdidas ocultas dentro de las transacciones rechazadas.
Así que explico varios métodos prácticos que utilizan los equipos de fraude para estimar la tasa de falsos positivos, incluyendo la simulación de reglas de fraude, la revisión manual, los grupos de control, la retroalimentación de los usuarios y la resolución de entidades.
Ninguno de ellos es perfecto.
Ese es, en cierto modo, el punto.
Triangulación
Combinas varias señales incompletas hasta que la imagen sea lo suficientemente buena para tomar decisiones.
La conversación también aborda las capas de decisión sobre fraude, los umbrales de los modelos, la monitorización de transacciones, la fricción operativa y por qué las herramientas de prevención de fraude a menudo generan puntos ciegos que los propios equipos no pueden medir por completo.
Y, sinceramente, cuando te das cuenta de cuántos falsos positivos nunca llegan a convertirse en etiquetas estructuradas, empiezas a entender por qué tantos equipos de fraude subestiman el problema desde el principio.
Conclusión clave
Cero falsos positivos es un mito.
El verdadero objetivo es entender de dónde provienen los falsos positivos, cuánto del problema está realmente bajo tu control y qué errores vale la pena corregir operativamente.
Una vez que los equipos de fraude puedan medir correctamente los falsos positivos en la detección de fraude, podrán dejar de adivinar y empezar a hacer concesiones de forma intencionada.
Menos mágico.
Probablemente mucho más útil.
¿No estás listo para dejar de hablar de mi, y espero que también tu, tema favorito? Suscríbete a The Saturday Fraud Strategist newsletter.
Episode transcript

Chen Zamir
00:11
Everyone agrees false positives are bad, but most teams don't know how to quantify them. Ask a fraud leader for last month's chargeback count, and you will get a precise number. Ask how many good customers were blocked by mistake, and you'll get a shrug, or worse, none. Why? Because the way we build fraud systems makes false positives invisible by design. Here's what I mean. If you approve a transaction, you get feedback. If it was fraud, you'll hear about it. If it was good, you will see the customer come back, spend more, log in again, do normal customer things. But if you block something, you get nothing. Best case, a customer complains, but even then that complaint will rarely make its way back into your data. It usually dies in a silo, buried in a support ticket, stuck in an inbox, or fading into the memory of a support rep. It almost never becomes a label attached to a specific event that fits into your model training pipelines or powers your dashboards. So, before we talk about reducing false positives, we have to talk about labeling them. So, how do you measure an error that the system is designed to hide? Let me start with a disappointing truth. There is no silver bullet. Measuring false positives is always an exercise in triangulation. You need to combine several imperfect methods to get a good enough picture for decision making. Let's get down to it. Teams naturally gravitate toward simulation because it's easy. You simply backtest your logic against historical data. Take a rule, or a rule set, or a workflow, and run it against the last six months of traffic. Look at all the events it would have declined, then cross-reference them against their final status, legit or fraud. Don't forget to account for fraud maturation, since chargebacks take time to materialize. Recent data is effectively unlabeled. A 30-day buffer is the minimum, and a 90-day window ensures your clean users are actually clean. Any transaction labeled clean that your rule would have blocked is a theoretical false positive. The appeal here is accessibility. You can run this in SQL or your fraud platform without deploying any new infrastructure. But simulation comes with important limitations. You are testing one rule in isolation, but in production that rule lives inside a complex decision stack with different rules, model thresholds, AI agents, manual reviews, third-party decisions, and so on. You also cannot backtest operational friction. Simulation assumes perfect code execution, but misses bugs, integration issues, or the behavior of upstream actors like issuers or processors. All of those can create false positives, and none of them are captured in a backtest. So, yes, simulate. It's a good start. Just be aware of its limitations. The second method is older, slower, and much more powerful. You manually review decline traffic. Instead of looking at the logic, you look directly at the impact. You take a sample of blocked events, either across the board or for a specific solution, and you ask an experienced fraud investigator to label them manually. This is essentially the same process you use to design your rules or hunt for new fraud patterns, just applied in reverse. Now, the limitations are obvious: it doesn't scale, it's time consuming, and it's expensive operationally. You also need experienced analysts, and even then, a percentage of events will remain as inconclusive gray cases. On the flip side, because this is an offline audit rather than a live decision, case-specific accuracy matters less. You also don't need to label everything. All you need is a sense of where you stand and where the worst offenders are. After all, it doesn't really matter if you conclude that the rule has an accuracy of 45% or 48%.
Chen Zamir
04:14
The third method is the one I consider the most underrated.
Chen Zamir
04:16
Linking. The idea is simple: in many cases, good users show up multiple times on your platform before or even after they get blocked. They may try again with a different card. They may reattempt onboarding with a different email address. They may transact again from the same device with an IP address you don't find risky. If you can link these events together and see the full sequence, you suddenly get an extremely strong signal that the original decline was a false positive. This linking can be straightforward: same user ID, different card. Same device, different email. Same IP and name, different device. Or it can be fuzzier, like a blocked user followed by a successful registration of their spouse. Once you have the basic infrastructure in place, the method scales beautifully. You simply run over your block population periodically and try to associate them with good events that happen before or after. The catch is that you need that infrastructure. You need to research a heuristic that would perform well. You need some kind of entity resolution solution. You need to be able to pull sequences of events over time. That is non-trivial work, but the ROI is massive. This really enables you to generate a continuous stream of high-precision false positive labels. It won't catch every false positive, but the ones it does catch will be very reliable. The fourth method is one that some might feel uncomfortable with: control groups. You take a randomized sample of traffic, typically around 1%, and whitelist it completely. No rules. No model-based declines. Normal reviews. Nothing. The population sails straight through to completion. Then you simply watch what happens. If your overall system performs well, you will see a meaningful amount of fraud in that control group. If, on the other hand, you notice that the control group's false positive rate is much higher than your expectations, then you know that you need to re-examine your setup. Control groups are powerful because they answer a very direct question: What would have happened if we removed the system entirely? The answer usually isn't pretty to look at, but it is an honest one. This approach, however, is only practical at scale. You need enough traffic that 1% or 2% still gives you statistically meaningful numbers in a timeframe that makes sense. You also need the budget to absorb the loss. It may not seem much, but if your incoming fraud pressure is 5% and you approve 1% of that, you just created five bps of loss before even considering chargeback fees. So this is a great tool to have, but it's likely only practical in your situation if your organization is mature and profitable enough. The fifth method, requesting direct user feedback, is a more opportunistic tactic, only available in select contexts. If you're looking at declined transactions on accounts you already know and trust, you can trigger a notification: We blocked a transaction ending in 1234. Was this you? But this isn't something you can do across the board. It's unusable at onboarding when you've never seen the user before. Asking a stranger if they are a fraudster doesn't really make much sense. Additionally, and I cannot stress this enough, do not give fraudsters a way to mark their own attempts as good. If a “yes, it was me” button automatically lifts the block, you haven't built a feedback loop. You've built a back door for fraudsters to find and exploit. But as an additional source of ground truth in very specific situations, such as failed login attempts or contact detail changes, this can be surprisingly helpful. If your conclusion is none of these methods are perfect, you are correct. That is the nature of the beast. But remember, you're not looking for a single magic metric that tells you the exact number of false positives in your system. You're looking to combine several independent indicators to build both accuracy and scalability. In practice, most teams end up with some combination of simulations for quick rule-by-rule sense checks, manual reviews for high-value flows and top offending solutions, linking as the main automation workflow once the engineering work is done, control groups for large populations where you can tolerate some control losses, and finally, user feedback in narrow, carefully chosen contexts. And if you mix these properly, you will end up with a workable estimate of your false positives broken down by at least a few important dimensions: product flow, traffic type, decision layer, and so on. And once you can measure the problem, you can finally start asking the right questions.
Chen Zamir
09:10
It's one thing to know that you have a false positive problem. It's another thing to know where it comes from. Is it mostly from rules? Your model threshold? Your human reviewers? A specific integration that corrupts IP addresses on mobile? A third-party payment processor that's hyper-aggressive on a specific region? In the second part of this series, we'll take the false positives you've managed to detect and bucket them by root cause. Wrapping up, let me just say that zero false positives is a myth. But you can still get to a point where every remaining false positive is either consciously accepted or outside of your sphere of influence. And that clarity alone is worth a lot.
View full transcript
