




Here's a question I've been asking fraud leaders lately: If I told you one of your AI agents had been degrading for six weeks, would you know?
Most would say no.
And that's a problem, because drifting agents are worse than no agents. They generate outputs that look fine from the outside while degrading the inputs that everything else depends on.
So how do you keep track of your agents? There are two things you need to be watching.
First, is the agent actually shortening your fraud reaction cycle?
Second, is it drifting in ways that won’t show up until it’s too late?
But the truth is that if you take a look at your average dashboard, it’s designed to answer something else entirely: is this agent even running? That is the least useful question to ask. Fraud AI agent metrics need to measure whether agents are improving outcomes, not just whether the workflow is technically active.
Use the fraud reaction cycle as the measurement target
I have written in the past that, in my view, the master KPI of fraud effectiveness is the reaction cycle: the time it takes your system to detect a gap and deploy a fix for it. Across its steps, agentic AI in fraud detection can do significant compression work.
But "can compress" and "is compressing" aren't the same thing. The first part of monitoring is measuring whether your agents are actually moving those time numbers in the right direction. That means AI agent performance metrics have to connect directly to detection speed, scoping speed, solution design, and deployment time.
The second part is catching drift early, before it shows up in cycle metrics. Because by the time a degrading agent moves your detection time or your solution design speed, the damage may already be weeks old.
That’s where AI governance becomes practical: teams need leading indicators that show when an agent is becoming less reliable before losses appear downstream.
Are your agents compressing the cycle?
Fraud AI agents can help with compressing your reaction cycle, but not necessarily in an even manner across the board. Here's what to track at each point where agents are making a difference.
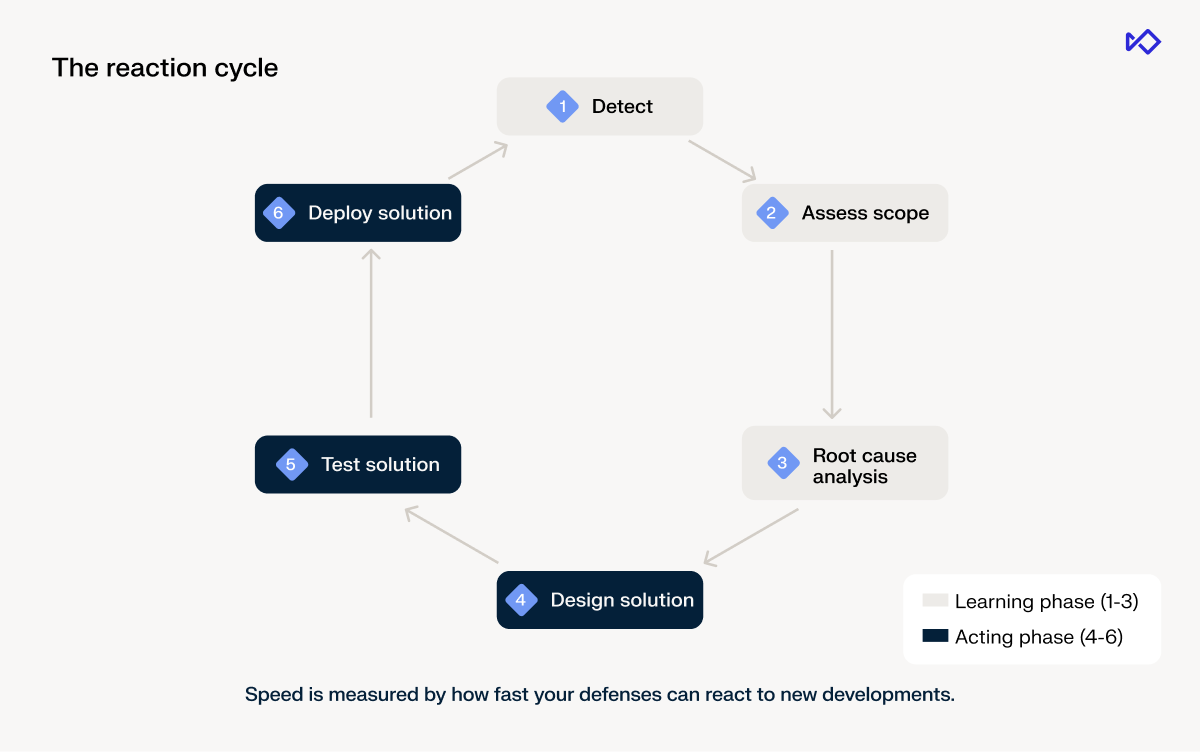
Detect coordinated fraud patterns faster
The first step in the fraud reaction cycle is recognizing there's a system gap. Without agents, this is slow by default. Alerts arrive, an analyst eventually notices a pattern, someone pulls related cases by hand. A new attack can run for days before anyone connects the dots.
With alert clustering and fraud detection automation, a new ring surfaces in hours. One alert triggers a search against known cases, matches get attributed to existing rings, and non-matches become new ring candidates.
What to track: Time from the first event of a new attack entering your system to your team recognizing it as a coordinated pattern. This should be one of your core fraud AI agent metrics. Most teams don't have this baseline yet so mine your past fire drills for it. How long did it take, in hindsight, between the first suspicious event and when the attack got flagged?
If this number isn't moving after you deploy clustering, the clustering isn't doing what it should. AI agent monitoring should make that visible quickly, not after weeks of degraded performance.
Scope fraud rings with AI agent monitoring
Once a pattern is flagged, the next question is: how big is this? How many accounts, what time period, what's the actual loss exposure? This is where agentic AI in fraud detection can move from spotting a signal to mapping the full population at risk.
Before agents, scoping was manual: an analyst pulling related cases, cross-referencing device data, building a picture account by account. With fraud AI agents, that same work can be compressed into a much shorter investigation window. And with case building, the ring's full extent gets mapped automatically. Related events get attributed, the affected population surfaces, and fraud detection automation helps uncover in near-real-time if it’s a suspicious anomaly or not.
What to track: Time from pattern flagged to ring fully mapped, user IDs, and total exposure. As an AI agent performance metric, this tells you whether the agent is reducing the work between recognition and action and where "one alert, 150,000 accounts" earns its meaning. Scoping that ring used to take days, now it's essentially a part of flagging the anomaly.
Design and test fraud fixes with AI agents
Once you understand the attack and how it's getting through, you need a fix. Fraud AI agents can take on the two steps that used to consume most analyst time: proposing the solution and proving it works.
The agent monitors incoming labels, identifies the pattern, proposes a rule, and runs the backtest, all before a human even reviews it. The analyst's job shifts from building the proposal to stress-testing and approving it. That is one of the highest-value uses of agentic AI in fraud detection: The system can move from signal to proposed control much faster.
What to track: Time from root cause identified to rule proposed and backtested, and time from proposal to approved and in production. The first tells you whether the agent is doing its job. The second often reveals an AI governance or system bottleneck, not an agent failure.
Cycle Stage | What agents compress | Metric to track |
Detect | Alert clustering surfaces rings in hours | Time: first suspicious event → pattern recognized |
Scope | Ring mapping automated vs. manual | Time: pattern flagged → full ring mapped |
Design | Rule proposed + backtested by agent | Time: root cause → rule proposed & backtested |
Deploy | Fewer bottlenecks in review | Time: proposal approved → in production |
Catching AI agent drift before the cycle metrics move
Here's the problem with cycle-level metrics: they lag. AI agent performance metrics tied to the fraud reaction cycle are necessary, but they are not enough on their own. A labeling agent that started misclassifying three weeks ago will eventually show up in your detection performance, model precision dropping or fraud rates drifting, but by the time those numbers move, you may have been training on bad data for weeks. This is the risk with fraud detection automation: the system can continue producing outputs even when the underlying quality has started to degrade.
A rule proposal agent generating worse output will show up in analyst rejection rates before it shows up in your cycle metrics, but only if you're watching the rejection rates.
What you want are signals that something is wrong before it shows up in cycle time. Those signals look different depending on whether the agent has a human in the loop or not.
Human-in-the-Loop (HitL) agents: The signals you'll see first
Investigation assistants, rule proposal systems, and segmentation recommendation agents all have humans reviewing every output before anything gets actioned. These Human-in-the-Loop agents are easier to monitor because every review creates a record of agreement, disagreement, or rejection and that review step creates a natural trail.
Override rate is your clearest leading indicator and one of the most useful fraud AI agent metrics for human-reviewed workflows. If investigators are ruling differently than the agent recommended more often than they used to, the agent is degrading. The key thing to understand is the order: override rate climbs before the average investigation time climbs. Good AI agent monitoring catches that shift while the problem is still early. It's earlier in the chain of causality, which means it's the earlier warning.
For rule and segmentation proposal agents, rejection rate is the equivalent. It’s another AI agent performance metric that shows whether the agent is still producing useful recommendations. Rejected proposals don't reach production, so they don't damage outcomes.
But a rising rejection rate means the agent is generating proposals that look plausible from the outside but fail human review, thereby consuming analyst time without producing results. Track it as a canary, not just as a cost concern.
Autonomous AI agents: What failure looks like in practice
Autonomous pipelines such as auto-labeling and alert clustering, don't have per-decision human review. When they fail, the failure is silent until something downstream breaks.
Here's what that actually looks like.
An auto-labeling agent starts misclassifying. Accounts that are legitimate get labeled as fraud, without anyone noticing. This is why AI governance has to account for autonomous AI agents differently than human-reviewed workflows. A few weeks later, a legitimate user whose account was frozen calls customer service. This is not a chargeback signal, but a dispute that traces back to a bad label.
A different scenario can be a case-clustering error that associates legitimate users with a fraud ring, and every account in that ring inherits the same ruling.
The damage is done before anyone sees it on a dashboard. Standard uptime checks will not catch this kind of failure; AI agent monitoring has to look at label quality, agreement, and distribution shifts.
That's why cross-source agreement matters as an early signal for autonomous AI agents. When your auto-labeling agent and another source, such as investigation rulings or rule-generated labels, are classifying the same events, track how often they reach the same conclusion.
If two sources that were aligned 90% of the time drop to 70%, something changed. As a fraud AI agent metric, cross-source agreement helps show when an automated label stream may no longer be trustworthy. You don't know which source is wrong yet, but you know to look before the damage compounds.
The other signal is distribution shifts, which are especially important for autonomous AI agents because there may be no human reviewer catching errors one decision at a time. If your labeling agent starts flagging 40% more events as fraud in a segment that hasn't seen any new attacks, that's worth investigating.
Something in the agent's inputs changed: a data quality issue, a schema change, a drift in the underlying population. The shift won't tell you what's wrong, but it tells you when and where to look.
Track fraud AI agent cost and ROI
This section applies to teams running their own agent infrastructure. If you're using a third-party fraud product, costs are abstracted away and this doesn't apply in the same way.
But if you do run your own agent, track cost per case, per proposal, and per label. These cost measures should sit alongside AI agent performance metrics, not replace them. When an agent starts consuming more compute for the same volume of work, something’s changed. That change may point to longer context windows, more enrichment calls, or an AI governance issue in how the workflow is being controlled.
More tokens processed often means longer context windows, more enrichment calls, or the agent re-running steps it used to complete in one pass. More compute also tends to mean a slower cycle, which is the opposite of what you're there for.
The thing you want to consider the most here is ROI, not just cost: is cost per label trending in the right direction relative to your Detect and Scope times? If the AI agent monitoring shows cost rising while the fraud reaction cycle stays flat, the agent is not creating the value it should. Is cost per proposal tracking the right way relative to Design and Test time? Rising cost with no corresponding cycle compression means the agent is getting less efficient at the job it was deployed to do. That should trigger a closer review of both fraud AI agent metrics and the governance controls around the workflow.
What AI agent monitoring actually looks like for fraud teams
I've outlined before that managing AI agents, including monitoring them, falls under the responsibility of your Fraud Analytics function. From a tooling perspective, there’s nothing new here.
Real-time alerts for threshold breaches. Override rate above baseline, cross-source label agreement below threshold, distribution shifts beyond a set tolerance. These alerts form the practical layer of AI governance for fraud detection automation. They should fire automatically from Slack, email, or wherever your team catches alerts, and get looked at the same day.
Weekly reviews of trend lines. The three fraud reaction cycle segment metrics, plus override and rejection rates for HitL agents. The dashboard should show direction as well as their current state. Fraud AI agent metrics are most useful when they show whether performance is improving, degrading, or quietly drifting over time. A number that's been moving the wrong way for three weeks is a different problem than a number that spiked once.
Monthly reports on cost and ROI, and on any autonomous pipelines that haven't had a sampling audit recently. Pull a random batch of agent decisions and review them manually. You don't need full coverage, rather, enough to catch a systematic drift before it compounds. This is one of the simplest AI governance practices for autonomous workflows.
One thing worth stating explicitly: as with any alerts system, expect an initial period of misfires as you learn how to fine-tune the sensitivity. Strong AI agent monitoring is not noise-free on day one; it gets better as your team learns which signals are meaningful. You want these misfires to be false positives, not silent failures to alert your team.
This means that the first couple of weeks will likely produce a lot of noise, and your team needs to prioritize the task of fine-tuning so you can get back to “business as usual” mode.
Back to the question
I started with a simple scenario: one of your fraud AI agents had been degrading for six weeks. Would you know?
If you're tracking override rates and rejection rates for your HitL agents, you'd know in days. If you're tracking cross-source agreement and distribution shifts for your autonomous pipelines, you'd know in a week or two.
At the same time, you can now also track the value agents create in a finer level of detail. Not only how many “person hours” you saved, but also how much quicker you detect and react to fraud. This too can be distilled into dollars you saved, especially when AI agent performance metrics are tied back to the fraud reaction cycle.
Get the full picture on fraud AI agents and AI governance
What you just read is the practitioner's companion to the whitepaper this series is drawn from, with a practical focus on fraud AI agents, AI agent monitoring, and the governance model needed to keep automation safe at scale. The whitepaper covers the full vision for what fraud ops becomes in an agentic world, the team structure the new model requires, the AI governance model that keeps continuous learning safe at scale, and the rollout sequence of what works, where teams break it, and how to defend it internally.
What are fraud AI agents?
Fraud AI agents are AI-powered systems that help fraud teams investigate patterns, cluster alerts, generate labels, propose rules, monitor thresholds, or support other fraud workflows. Unlike simple automation, fraud AI agents can assist with multi-step tasks across the fraud reaction cycle, from detecting a gap to helping teams design and deploy a fix.
Why does AI agent monitoring matter for fraud teams?
AI agent monitoring matters because fraud AI agents can drift quietly while still appearing to work. A dashboard may show that an agent is running, but that does not mean its outputs are accurate, useful, or improving fraud outcomes. Fraud teams need monitoring that tracks performance, drift, override rates, rejection rates, agreement between label sources, and changes in distribution.
What are the most important fraud AI agent metrics?
The most important fraud AI agent metrics depend on the agent’s role. For detection and scoping agents, teams should track time from first suspicious event to coordinated pattern recognition, and time from pattern flagged to full ring mapping. For human-in-the-loop AI agents, override rate and rejection rate are key. For autonomous AI agents, cross-source label agreement, distribution shifts, sampling audits, cost per label, and cost per case are important signals.
How does the fraud reaction cycle apply to fraud AI agents?
The fraud reaction cycle measures how long it takes a fraud system to detect a gap and deploy a fix. Fraud AI agents should be evaluated by whether they compress that cycle. If an agent helps detect coordinated fraud patterns faster, scope exposure sooner, propose rules earlier, or move fixes into production more quickly, it is creating measurable value.
What is the difference between human-in-the-loop AI agents and autonomous AI agents?
Human-in-the-loop AI agents have a person reviewing each output before anything is actioned. Examples include investigation assistants, rule proposal systems, and segmentation recommendation agents. Autonomous AI agents do not have per-decision human review. Examples include auto-labeling and alert clustering pipelines. Because autonomous AI agents can fail silently, they need stronger monitoring through agreement checks, distribution shifts, and sampling audits.
How can fraud teams detect AI agent drift?
Fraud teams can detect AI agent drift by watching leading indicators before fraud losses or cycle metrics move. For human-in-the-loop AI agents, rising override rates or rejection rates can show that agent quality is degrading. For autonomous AI agents, falling cross-source label agreement, unusual distribution shifts, and failed sampling audits can signal drift before downstream systems are affected.
How does agentic AI in fraud detection improve reaction time?
Agentic AI in fraud detection can improve reaction time by helping teams recognize suspicious patterns, connect related events, map fraud rings, generate labels, and propose fixes faster than manual workflows. The goal is not only to automate individual tasks, but to shorten the time between detecting a fraud gap and deploying a response.
How does fraud detection automation create new monitoring risks?
Fraud detection automation creates new monitoring risks because automated systems can continue producing outputs even when quality is degrading. A labeling agent may misclassify accounts, or a clustering agent may group legitimate users with a fraud ring, without any immediate human review. That is why AI agent monitoring needs to measure output quality, not just system uptime.
What AI agent performance metrics should fraud teams track?
Fraud teams should track AI agent performance metrics that connect to actual fraud outcomes. These include detection time, scoping time, time from root cause identified to rule proposed, time from proposal to production, override rate, rejection rate, cross-source label agreement, distribution shifts, cost per case, cost per proposal, cost per label, and sampling audit results.
How does AI governance apply to fraud AI agents?
AI governance gives fraud teams a structured way to manage how fraud AI agents are monitored, reviewed, escalated, and improved. In practice, that means setting thresholds for override rates, rejection rates, agreement levels, and distribution shifts, reviewing trend lines weekly, auditing autonomous agent decisions, and making sure automation remains safe, explainable, and aligned with fraud risk goals.