
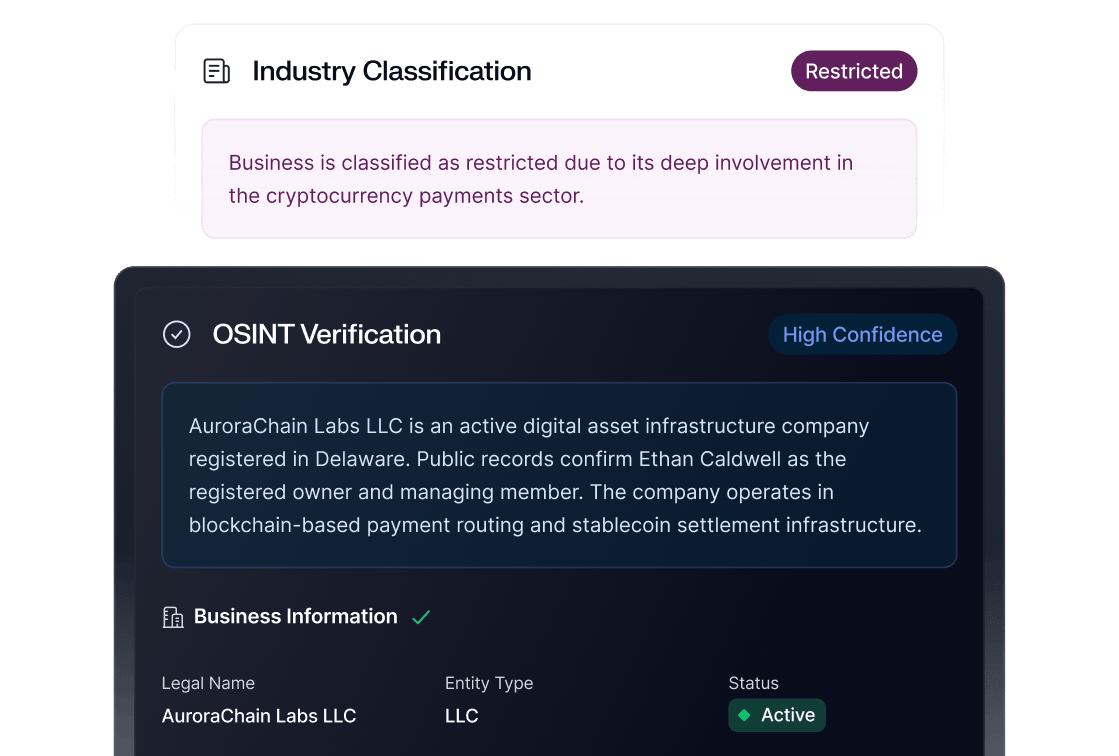





When people talk about reducing false positives, they usually jump straight to tactics: tune rules, adjust thresholds, add exemptions, relax the model, redirect edge cases to manual review, and so on. All of that is part of the work, but none of it should be the starting point.
If you’ve made it this far in the series (catch up on part 1 and part 2 here), you’ve already done the two pieces of work that most teams skip:
- You’ve built a reasonably accurate measurement of your false positives, even though your system hides them by default.
- You’ve mapped those false positives into buckets: by actor, by solutions, by flow, by data quality, and by what is or isn’t under your control.
That’s the groundwork. Now you’re ready to tackle the main course: fixing the parts of the system that are misbehaving.
But this is where we should approach the work with discipline. Otherwise, you’ll end up making changes that don’t matter, overlooking changes that would have mattered, or worst of all, opening the door for additional fraud without realizing it.
This blog focuses on the fixes that operate inside your fraud system.
Review your top offenders through manual review
One of the best ways to ground yourself before making any change is to go back to manual review. Pick the rule, model threshold, or AI agent that fires most frequently and manually inspect a sample of the events it blocked (50 to 100 should be enough in most cases).
What you’re trying to answer are often very basic questions:
- Is this rule actually as inaccurate as we think?
- Do we still want this rule to exist at all?
- If it exists, should it still make automated decisions, or should it feed into manual review instead?
- If it should remain automated, what would it take to reduce its false positives without materially increasing our fraud losses?
Each of these questions is business-specific. There is no universal threshold for “good enough.”
Sometimes your FraudOps team can take on the additional manual reviews. Sometimes you have no manual reviews at all as part of your process.
And sometimes a rule needs to remain automated even if it’s noisy, because you simply cannot afford to manually review that volume.
But you need clarity before you change anything. The worst case is thinking a rule is fine because it “looks logical,” only to discover under manual review that it’s blocking overwhelmingly legitimate traffic.
You can’t reason your way through these situations. You have to look.
Most importantly, this isn’t just about validating you’re fixing a real problem. It’s about showing you how to do it.
Three decision paths for every misbehaving fraud rule or model
Once you’ve reviewed the evidence, almost every misbehaving solution falls into one of three categories:
1. The fraud rule should not exist at all.
This happens more often than teams admit.
You have logic in your system that:
- Catches a small population
- Doesn’t block much fraud
- Generates a disproportionate amount of false positives
- Exists mostly because someone added it during a crisis and no one revisited it
Removing these rules feels uncomfortable the first few times you do it. But if the fraud they catch is negligible and the false positives are significant, turning them off is one of the cleanest, safest ways to improve your system.
This is your low-hanging fruit.
2. The fraud rule should exist, but it should no longer make automated decisions.
This is common with mid-accuracy logic that still captures meaningful fraud, but not reliably enough to block without human review.
If you have manual review capacity, and if this particular logic tends to produce events your analysts are comfortable judging, then sending it to case management instead of auto-decline can be the perfect compromise.
You preserve fraud coverage, reduce false positives, and put a human in the loop that can observe performance changes in real time.
The cost, of course, is operational. This only works when you have a clear picture of your analysts’ accuracy and your queue’s capacity.
3. The fraud rule should exist and stay automated, but its logic needs to be improved.
This is the most interesting scenario. It’s also the most common.
The logic captures real fraud. It’s necessary. It’s effective. But it’s also catching a meaningful number of legitimate users.
So you need to refine it. The question is how.
Path 1: Remove the rule | Path 2: Reroute to manual review | Path 3: Refine the logic | |
When to use | Low fraud catch, high false positives; legacy or crisis-era logic no one revisited | Mid-accuracy rule that catches meaningful fraud but isn't reliable enough to auto-decline | High fraud catch and necessary rule, but also catching a meaningful number of legitimate users |
Prerequisite | Confirmed negligible fraud impact through manual review | Available analyst capacity and clear queue bandwidth | Clean separation between fraud and false positive patterns (validated via "mirror image" method) |
Action | Turn off the rule entirely | Redirect flagged events to case management instead of auto-decline | Build exclusions derived from false positive population, validated against fraud population |
Risk | Minimal if fraud volume is truly low | Operational cost; depends on analyst accuracy and queue capacity | Exclusion could release fraud if not properly validated |
Validation | Monitor fraud rates post-removal | Track analyst decision accuracy and queue load over time | Shadow mode / challenger rule testing before full deployment |
The “mirror image” of fraud detection: How to build exclusions properly
The process for improving a false-positive-heavy rule is almost identical to the way you design a new fraud rule, just in reverse.
Think about it. When you design a fraud rule, you:
- Review a set of confirmed fraud cases.
- Identify the pattern they share.
- Compare that fraud pattern to the general good population.
- Build logic that captures the fraud without scooping up too many good events.
To reduce false positives, you do the same thing but with the opposite goal in mind. You:
- Review a set of confirmed false positive cases.
- Identify their repeating patterns.
- Compare those patterns to the fraud cases to make sure the separation is real.
- Build exclusions or refinements that capture that separation without “releasing” too much fraud.
This last step is crucial. It’s not enough to say, “A lot of false positives have characteristic X.” You need to prove that your fraud cases don’t exhibit that same characteristic. Otherwise, your exclusion will undermine your fraud detection.
The beauty of it? If you’ve worked through the steps without skipping any, you already did this manual review while validating the false positive metrics.
Let’s take an example. Suppose you have a very standard mismatch rule:
“Decline if the IP country doesn’t match the account country.”
This is common, and it’s often noisy. Now imagine you manually review a sample of 100 events this rule blocked. After tagging them, you notice:
- 30 were fraud
- 70 were legitimate
- And of those 70 legitimate events, 20 involved U.S. users whose IP addresses resolved to Canada
20 out of 70 is a meaningful pattern.
Maybe your business has a large U.S.-Canada commuting demographic. Maybe VPNs for Canadian endpoints are common. Maybe part of your user base works close to the border. For whatever reason, this specific mismatch (U.S. account → Canadian IP) seems to produce a lot of false positives.
If, in your fraud cases, you see little to no fraud coming from that same U.S. → Canada pattern, then you have a clean separation. That means you can safely introduce an exclusion:
“Decline if (IP country doesn’t match the account country) AND NOT (IP country matches CA and account country matches US)”
Or better yet, broaden it slightly to include neighboring-country logic, depending on your business footprint and available features.
The point is that the exclusion is derived from reviewing your false positive population and is validated against your fraud population.
This is how you refine rules without opening dangerous gaps.
Test logic changes before you release them
Any time you change fraud logic, even if it's just an exclusion on an existing rule, you’re changing your risk posture. This is just like when you release a new rule completely from scratch.
So before you release the new version, test it.
Shadow mode and challenger rules are your friends. Keep the existing rule active, but run your refined rule in parallel for a few days. Measure the differences:
- How many additional events would it have allowed?
- How many of those events matured into fraud?
- How many false positives would it have prevented?
If the results hold over time you can deploy with confidence. If not, adjust.
How much time should you monitor these changes?
Ideally, enough to gain a good measure of how fast fraud matures in the new version and whether that’s inline or not with the original version. If you’re really pressed for time, you may want to consider manually reviewing random samples.
When dealing with data issues
As we explored in part 2 of this series, sometimes the root cause of false positives is not faulty logic, but corrupted data.
Best case, you’ve already identified it in your groundwork analysis. Worst case, you went through all of the motions, just to figure it out on your detailed manual review.
When this is the identified root cause you have two options, depending on whether the data issue is fixable in the near term.
Option 1 - Fix the data quality issue itself
If the corrupted field is under your control, be it your SDK, your internal integration, or your infrastructure, then the best long-term solution is to repair the data.
That might mean fixing an API payload, adjusting an SDK version, or working with a product team to plug a hole.
It may take a few days or a few weeks, depending on your organization. But once the data is fixed, the rule will often start behaving correctly again.
Also, it’s likely that you also solved an array of issues that were plaguing other departments as well at the same time.
Option 2 - Adjust the fraud logic for that flow
Not all data issues are internally fixable. Sometimes they originate from external parties that you just cannot control. Or in the most frustrating cases, you do control these issues, but there’s no fix in sight.
If you cannot fix the underlying data soon, then you may need to adjust your fraud logic specifically for that flow. Once more, you can consider a few alternatives:
- Exclude the problematic flow from the rule altogether.
- Lower the rule’s weight or change its impact.
- Move those cases to manual review.
Fraud prevention is more pragmatic than elegant, and sometimes it’s not about being right, it’s about being smart.
What you should have by the end of part 3
At this stage, you should be able to:
- Identify your highest-volume false positive drivers.
- Diagnose whether each one should be removed, re-routed, or refined.
- Apply the “mirror image” method to build effective, safe exclusions.
- Distinguish between genuine misbehavior and data-quality issues.
- Validate every change through shadow mode before releasing it.
This is the tactical heart of false positive reduction: dealing with the specific actors inside your system.
But there’s one more layer we haven’t touched yet, an architectural layer that operates above rules, models, agents, and even manual review.
That layer is where part 4 takes us. See you there.


