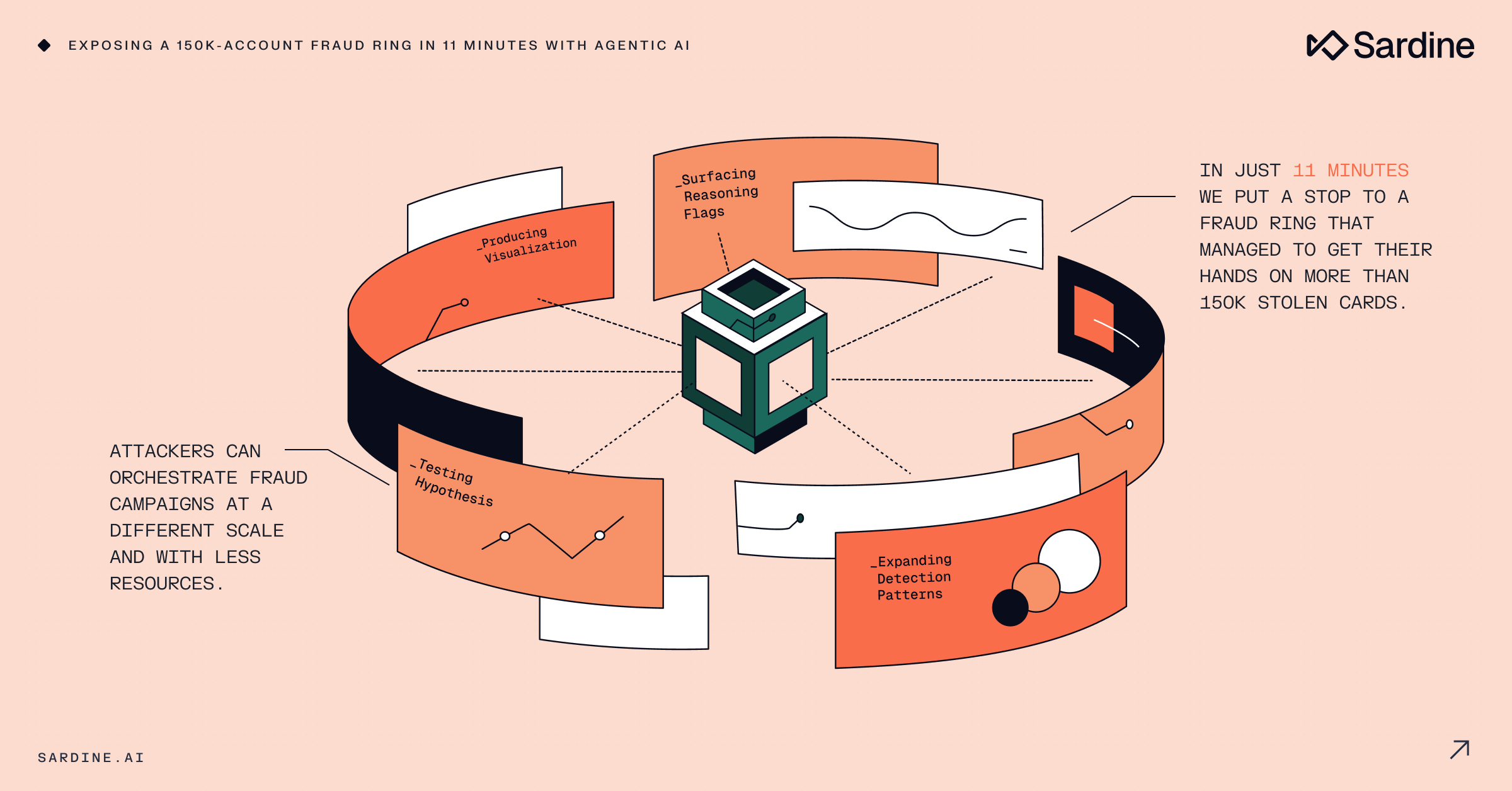




Anthropic just announced a finance-agents release. Among the things they pushed live: a KYC screener.
If you do KYC for a living, you probably saw the headlines. They were big. But I want to do something more useful than amplify them.
This post does two things. It explains what Anthropic actually shipped, separated from how it’s been reported. And it helps you figure out whether the thing they shipped fits the problem you’re trying to solve, or whether you need something different.
The short version: Anthropic’s release is good news. It confirms what we already suspected, that fincrime is a natural fit for agentic AI. At this point, the question isn't whether to use AI in KYC. That's settled. The question is which form of AI actually fits your operation.
Let’s get into it.
What Anthropic actually released
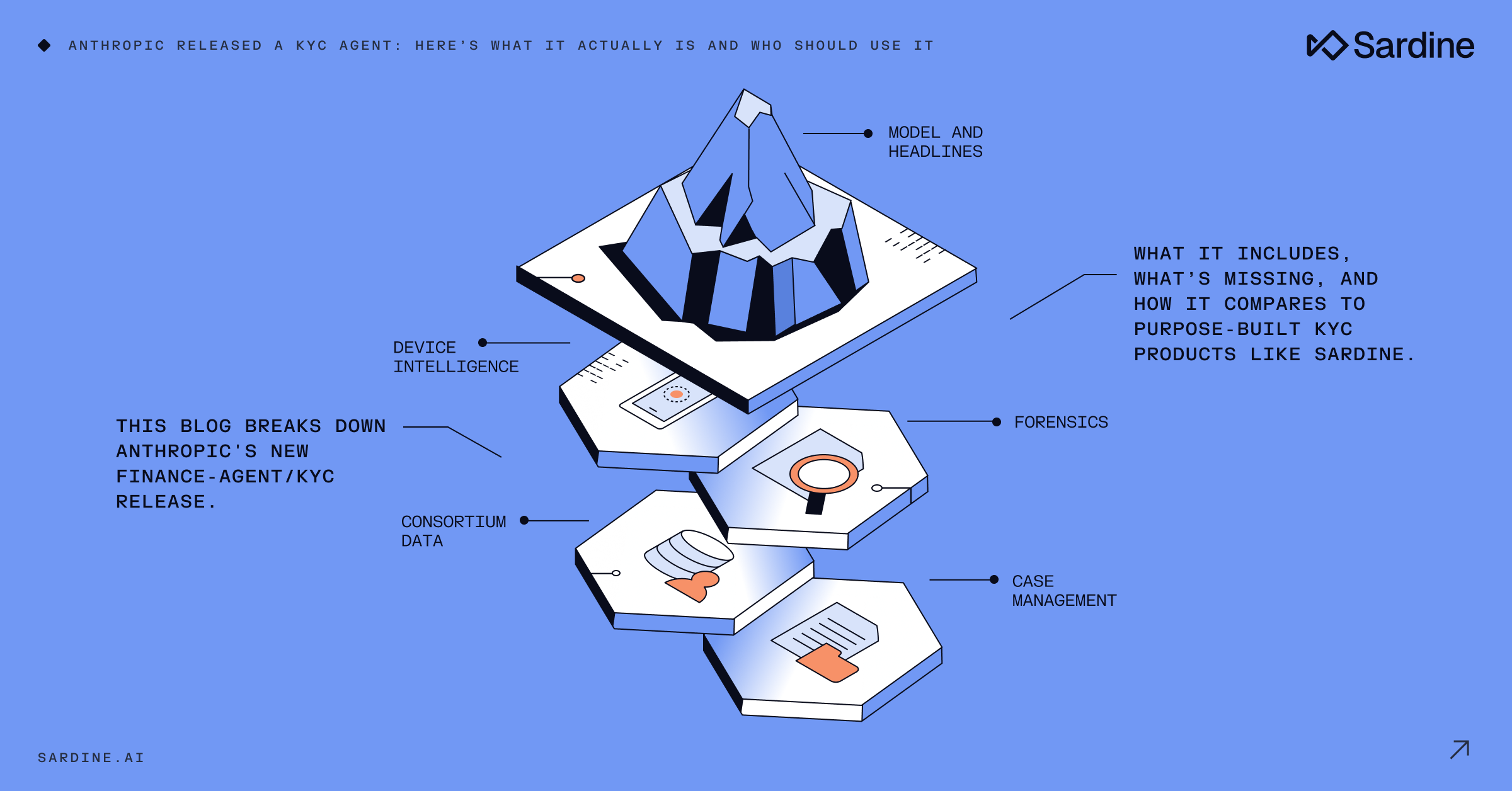
It’s a starting point, not a finished product. When you strip away the architecture talk, here's what's in the box.
The capability
It runs a four-step workflow on every onboarding record. A doc-reader pulls structured fields out of your KYC packet. The rules engine applies your firm's KYC rules against those fields. A screening step then checks every named party, including sanctions, PEP, adverse media, through a screening MCP that you connect.
The escalator bundles whatever needs human attention into a compliance packet. The output is structured JSON, like risk rating, disposition, missing documents, escalation reasons, rule outcomes, which is easy to drop into a review queue.
How you deploy it
Two flavors from the same template. An analyst-side plugin that lives in Microsoft Office and supports a human reviewer. Or a server-side Managed Agent that runs autonomously, with a credential vault, scoped tool permissions, and a full audit log baked in. Same prompt, two runtimes. That part is genuinely well-designed.
You can pilot under human oversight, then graduate to autonomous as you build confidence, without rewriting the agent.
That's the release. A reasoning layer with a clean output contract, built to plug into whatever stack you've already got. But the "whatever stack you've already got" part is doing a lot of work in that sentence.
What’s not in the box
Anything that requires purpose-built tooling for KYC.
The template ships with no document forensics. ID tampering detection, such as font analysis, hologram verification, microtext checks, fraudulent rendering detection, that’s a specialized ML problem with its own training data. The Anthropic agent reads documents using the foundation model’s vision and OCR. That’s fine for “what does this document say.” It’s not the same as “is this a real passport or a Photoshop job.”
Liveness, deepfake detection, selfie-replay, 3D-mask checks? None of that is here. If you're onboarding consumers and a deepfake walks through your front door, the foundation model isn't going to catch it.
Device intelligence is also absent. From behavior biometrics to true IP, true OS, and true age, the template wasn't designed to see any of it. The fact that a user came in from an emulator on a residential proxy, sharing a device with three other accounts? That signal simply doesn't exist here.
No KYB. No UBO. No Secretary of State checks, no EIN/TIN, no address analysis, no industry classification, no web presence checks. Business onboarding is a separate problem, as this template addresses individual identity.
The KYC-rules skill formalizes your policy; it doesn't ship with a pre-built CIP rule library or a back-testing framework you can run against 30/60/90-day windows. What you bring is what you get.
There’s also no case management UI. The template “packages escalations” and hands them off. To what? To whatever review system you’ve already built. If you don’t have one, you’re building one.
And beyond onboarding, there's nothing here for the customer lifecycle: no re-screening, no risk rating updates, no ongoing monitoring. No consortium data, no connections graph across billions of devices and consumers.
This isn’t a knock on the release. It’s a clarification of what the release is. Anthropic is shipping the reasoning layer. The bank, or the vertical KYC vendor the bank is using, ships the data, signals, forensics, and operational substrate the reasoning runs on top of.
Capability | Anthropic KYC-screener | Sardine Doc KYC Agent |
Form factor | Reference architecture; plugin or managed agent | Productized agent on Sardine’s platform |
Document forensics | Foundation-model OCR and vision | Purpose-built ID tampering detection |
Liveness / deepfake | Not in scope | Native |
Device + behavior signals | None natively | TrueIP, TrueOS, behavior biometrics |
Watchlists (OFAC/PEP/SDN) | Not bundled | Built-in screening + sanctions re-screening + automated alert resolution. |
KYB / UBO | Out of scope | Bundled |
Pre-built rule library | Bring-your-own | Hundreds of CIP rules + back-testing |
Case management | Not provided | Integrated |
Auto-resolution | Firm-dependent | 88% claimed; 95%+ automated sanctions screening at one sponsor bank |
The reasoning layer is just the foundation
Here’s something I want to say plainly, because most of the coverage is glossing over it.
Reasoning models are getting commoditized. Fast.
Five years ago, the model that could read an entity file, cross-reference five rules, and explain its disposition in fluent English was a moat. Today, three labs ship something that can do that, and the gap between the leader and number three is small enough that customers will swap.
The model is one input to a KYC decision. It’s not the system.
If you take an LLM, even a great one like Opus 4.7, and you point it at a stack of customer documents with no calibration, you’ll discover something quickly: it tends to think a lot of things look suspicious. Variations in document quality, names that transliterate strangely, dates that follow non-US conventions, addresses with apartment numbers in unusual formats, all of these read as anomalies to a model that hasn’t been trained on what normal looks like in your customer base. We covered this topic in a recent blog.
I myself have three PayPal accounts because I’ve lived in three countries. To a model with no context, that’s a serious red flag. To anyone who’s done this work and knows their customer base, that’s pretty normal.
The fix is calibration: feeding the model a body of true positives and true negatives from production, rigorously labeled, so it learns the difference between fraud and fraud-shaped. We’ve built an Agentic Oversight Framework around this; the whitepaper describes the validation loop in detail. The point isn’t that we’re the only ones who can do it. The point is that this is the work, and it doesn’t come for free with a great foundation model.
The oversight question
You can’t deploy an autonomous agent against KYC and walk away. Anthropic knows this, which is why their Managed Agents path ships with a per-tool credential vault, scoped permissions, and a full audit log. That’s real. It’s a meaningful improvement over earlier autonomous-agent infrastructure.
But an audit log is not a case manager.
A case manager is the substrate where the agent’s decisions, the analyst’s overrides, the customer’s evidence, the timeline of communications, the escalation paths, and the feedback loop into the next model version all live. It’s where a regulator points when they ask: show me how you decided to clear this customer.
At Sardine, this is the part I think about most. We work with a top sponsor bank, that sponsors major fintechs, where the agent resolves 95%+ of sanctions screening alerts automatically. Resolves them, leaves a comment in the case manager explaining why, and escalates the cases that genuinely need a human. The human reviews the agent’s reasoning, agrees or disagrees, and leaves their own comment. Everything is timestamped. Every disagreement gets fed back into the next training and tuning cycle for the agent.
That loop is the product. The model that does the inference inside the loop is one component of it, swappable and improvable. The loop itself is what compliance teams and regulators care about.
Anthropic’s template doesn’t include this loop. They’ve done the auditable-execution part: the credential vault, the per-tool permissions, the long-running session log. The case management UI, the analyst override, the disagreement-to-retrain pipeline are the buyer’s job to build.
The questions you need to answer before plugging public AI into customer data
These don’t get talked about enough.
If you’re considering putting a public foundation model in the path of customer onboarding, you need clean answers to four questions. Not “the vendor said it’s fine.” Clean answers, in writing, that your CISO and compliance officer can sign.
- When the agent runs over your customer’s PII and transaction data, where does that data go? Is it scoped to a tenant, or does it transit a shared inference path? Where are the logs?
- Are you uploading customer data into a global, public AI platform, and if so, what does the contract say about retention, access, and breach liability?
- How do you comply with on-soil jurisdiction requirements? If your regulator requires data not to leave the country, and your inference happens in another country, you have an answer to give. What is it?
- Will the platform train on your data? Yours, your competitors’, and the data both flowing through tomorrow? If the answer is no, do you have it in writing? If the answer is conditional, what are the conditions?
These aren’t gotchas. They’re standard procurement questions for any vendor that touches customer data. They get harder when the vendor is also a foundation model lab. They get harder still when the model itself is a competitive asset that benefits from training data.
The Managed Agents path partially answers these, and the credential vault and the long-running session model are designed for this kind of scrutiny. But partial answers don’t equal answered. If you go this route, plan for a real procurement cycle.
So who is this actually for?
Now we get to the useful part.
The Anthropic template is built for a specific buyer. It’s a buyer with strong in-house engineering, an existing data stack (KYC vendors, market data, internal CRMs), an existing review operation, and an appetite for owning the reasoning layer end-to-end. The customers that Anthropic names in the announcement like Citadel, BNY, and Carlyle fit that profile exactly. They don’t need a turnkey KYC product; they need a flexible reasoning layer they can compose into their own workflow.
For that buyer, the KYC-screener is a real upgrade over what they had. They get:
- A reasoning model leading the Vals AI Finance Agent benchmark.
- Deep integration with Microsoft 365 surfaces like Excel, Word, and Outlook where their analysts already live.
- A clean composable architecture; skills, connectors, and subagents that swap independently.
- Both desktop and server-side deployment paths from the same template.
- Per-tool credential vault and full audit log via Managed Agents.
If you’re that buyer, the right move is probably to take the template seriously, do a real proof of concept against your existing stack, and figure out which of the missing pieces (forensics, device, watchlists, case manager) you fill in via best-of-breed connectors versus build versus partner.
Sardine is built for a different buyer. It’s a buyer that needs production KYC running by next quarter, not next year, without first hiring a team of engineers to compose a custom stack. This looks like fintechs, neobanks, large banks, payment processors, and crypto exchanges. The buyer cares about outcomes (auto-resolution rate, false-positive rate, time-to-clear) more than owning the orchestration layer.
For that buyer, Sardine ships:
- Document forensics built specifically for ID tampering
- Liveness and deepfake detection
- Device intelligence and behavior biometrics that feed into the doc decision
- Watchlist screening with thresholding and ongoing monitoring
- Ongoing sanctions re-screening, not just point-in-time checks at onboarding
- KYB/UBO bundled with KYC
- A pre-built CIP rule library with no-code editing and 30/60/90-day back-testing
- A case manager designed for analyst-agent collaboration with audited disagreement loop
- Sonar consortium data across billions of devices and consumers
These aren't hypothetical capabilities. Within our own crypto onramp, our IDV Agent runs on the same stack and hits ~95% automation on identity verification, the same rate we see at that sponsor bank customer running automated sanctions screening.
There’s also a third option that’s actually interesting: run both. Use Anthropic’s template at the orchestration layer for cases where the strength of the reasoning model matters most, like complex entities, narrative-heavy escalations, regulatory drafting, and call Sardine via MCP connector for the data, forensics, and device layers. That’s a partnership, not a head-to-head. I expect we’ll see customers do this within a year.
What this means
I’ll close with the thing I told my team when the announcement hit.
This is good news. The lab behind Claude just publicly validated that fincrime is a natural fit for agentic AI. The argument we’ve been making for two years, that AI agents reduce false positives, accelerate clearance, and free up human analysts to do the work that actually requires judgment, is now the consensus position of the industry’s most influential model lab.
The reasoning layer is going to keep getting better, and it’s going to keep getting cheaper. That’s fine. The defensible part of a KYC product was never going to be “we have the best model.” It was always going to be the data, the signals, the rules library, the case management, the regulator relationships, and the operational scar tissue that comes from running this stuff in production for real customers at real scale.
If you’re a buyer, the right question isn’t which model is best, because that race resets every six months. The right question is: what does my system look like a year from now, and which form factor (composable platform, vertical product, or both) gets me there the fastest?
Then build for that.